
1EdTech OneRoster®: Best Practices and Implementation Guide
1EdTech Final Release
Version 1.1
| Date Issued: | 17th April, 2017 |
| Latest version: | http://www.imsglobal.org/lis/ |
IPR and Distribution Notices
Recipients of this document are requested to submit, with their comments, notification of any relevant patent claims or other intellectual property rights of which they may be aware that might be infringed by any implementation of the specification set forth in this document, and to provide supporting documentation.
1EdTech takes no position regarding the validity or scope of any intellectual property or other rights that might be claimed to pertain to the implementation or use of the technology described in this document or the extent to which any license under such rights might or might not be available; neither does it represent that it has made any effort to identify any such rights. Information on 1EdTech's procedures with respect to rights in 1EdTech specifications can be found at the 1EdTech Intellectual Property Rights web page: http://www.imsglobal.org/ipr/imsipr_policyFinal.pdf.
Copyright © 2017 1EdTech Consortium. All Rights Reserved.
Use of this specification to develop products or services is governed by the license with 1EdTech found on the 1EdTech website: http://www.imsglobal.org/speclicense.html.
Permission is granted to all parties to use excerpts from this document as needed in producing requests for proposals.
The limited permissions granted above are perpetual and will not be revoked by 1EdTech or its successors or assigns.
THIS SPECIFICATION IS BEING OFFERED WITHOUT ANY WARRANTY WHATSOEVER, AND IN PARTICULAR, ANY WARRANTY OF NONINFRINGEMENT IS EXPRESSLY DISCLAIMED. ANY USE OF THIS SPECIFICATION SHALL BE MADE ENTIRELY AT THE IMPLEMENTER'S OWN RISK, AND NEITHER THE CONSORTIUM, NOR ANY OF ITS MEMBERS OR SUBMITTERS, SHALL HAVE ANY LIABILITY WHATSOEVER TO ANY IMPLEMENTER OR THIRD PARTY FOR ANY DAMAGES OF ANY NATURE WHATSOEVER, DIRECTLY OR INDIRECTLY, ARISING FROM THE USE OF THIS SPECIFICATION.
Public contributions, comments and questions can be posted here: http://www.imsglobal.org/forums/ims-glc-public-forums-and-resources/learning-information-services-oneroster-public-forum.
© 2017 1EdTech Consortium, Inc.
All Rights Reserved.
Trademark information: http://www.imsglobal.org/copyright.html
The 1EdTech Logo and OneRoster are trademarks of the 1EdTech Consortium, Inc. in the United States and/or other countries.
Document Name: 1EdTech OneRoster® 1.1 Best Practices and Implementation Guide
Revision: 17th April, 2017
Table of Contents
1. Introduction
1.3 Structure of this Document
1.5 Nomenclature
2. OneRoster Interoperability Architecture
3. Common REST/CSV Adoption Best Practices
3.1.1 Sourced Identifiers
3.1.2 Resources VendorId
3.1.3 User Ids
3.1.4 School and District identifiers
3.2 The 'enabledUser' Attribute in the 'Users' Class
3.3 Status Fields Values Implications
4. CSV File Handling Best Practices
4.1 File Encoding and File Ordering
4.3 Round-tripping Between V1.1 and V1.0
4.4 Ensuring Semantic Consistency
4.5 Extending the Data Model for the CSV Files
4.5.1 Extending the Vocabularies
4.5.2 Extending the Data Model
4.6 Suggested Extension Fields
4.6.1 'courses.csv' Data Model
4.6.2 'orgs.csv' Data Model
4.6.3 'users.csv' Data Model
5. REST-based Exchanges Best Practices
5.1 Compatibility of the REST API between Versions 1.0 and 1.1
5.2 Authentication
5.3 Read, Write, Delete Choreography Implications
5.4 Matching End-to-End Service Capabilities
6.1 Establishing and Maintaining a District Repository for K-12 Information
6.2 Making Roster Information Available
6.3 Identification of Resource Allocation
6.4 SIS/LMS Exchange of Gradebook Information
6.5 Real-time Bulk Exchange of OneRoster Information
6.6 Batch Bulk Exchange of OneRoster Information
Appendix A Key Terms and Definitions
1. Introduction
1.1 Scope and Context
The purpose of this document is provide the collected and collated best practice recommendations for the adoption of the 1EdTech OneRoster 1.1 standard. This information was produced during the development of the standard and from the feedback of the 1EdTech Members who have the adopted OneRoster.
1.2 Status of this Document
This document is the Final Release, meaning the technical solution is now made available as a public document and as such several 1EdTech Members have aleady successfully completed conformance certification at the time of release of the specification.
1EdTech strongly encourages its members and the community to provide feedback to continue the evolution and improvement of the OneRoster standard. To join the 1EdTech developer and conformance certification community focused on OneRoster please visit the 1EdTech OneRoster Alliance online here: http://www.imsglobal.org/lis/index.html
Public contributions, comments and questions can be posted here: Public OneRoster Forums.
1.3 Structure of this Document
The structure of the rest of this document is:
| 2. OneRoster Interoperability Architecture | The assumed architecture for the exchange of OneRoster-based data; |
| 3. Common REST/CSV Adoption Best Practices | The set of recommendations that are relevant to both the REST/JSON service and CSV file bindings; |
| 4. CSV File Handling Best Practices | The set of recommendations for the adoption of the CSV-based data exchange; |
| 5. REST-based Exchanges Best Practices | The set of recommendations for the adoption of the REST/JSON service binding. |
| 6. Realising the Use-cases | A descrption of how the OneRoster standard is used to realise a number of use-cases. |
| Appendix A - Key Terms and Definitions | A short description of various key terms and definitions used for OneRoster. |
1.4 Related Documents
| [AfA PNP, 10] | Access For All Digital Personal Needs and Preferences Description for Digital Delivery Information Model 2.0, R.Schwerdtfeger, M.Rothberg and C.Smythe, 1EdTech Consortium, Inc., April 2010, https://www.imsglobal.org/accessibility/accpnpv2p0/spec/ISO_ACCPNPinfoModelv2p0.html. |
| [OneRoster, 17a] | OneRoster Specification and REST Binding v1.1, P.Nicholls and C.Smythe, 1EdTech Consortium, Inc., April 2017, http://www.imsglobal.org/lis/imsonerosterv1p1/imsOneRoster-v1p1.html. |
| OneRoster, 17b] | OneRoster 1.1 CSV Tables, P.Nicholls and C.Smythe, 1EdTech Consortium, Inc., April 2017, https://www.imsglobal.org/lis/imsOneRosterv1p1/imsOneRosterCSV-v1p1.html. |
| [OneRoster, 17c] | OneRoster 1.1 Conformance and Certification, C.Smythe and P.Nicholls, 1EdTech Consortium, Inc., April 2017, https://www.imsglobal.org/lis/imsOneRosterv1p1/imsOneRosterConformance-v1p1.html. |
| [RFC1951] | DEFLATE Compressed Data Format Specification 1.3 (RFC 1951), P.Deutsch, IETF, May 1996, https://www.ietf.org/rfc/rfc1951.txt. |
| [RFC3629] | UTF-8: A Transformation Format of ISO 10646 (RFC 3269), F.Yergeau, IETF, November 2003, https://www.ietf.org/rfc/rfc3269.txt. |
| [RFC4180] | Common Format and MIME Type for Comma-Separated Values (CSV) Files (RFC 4180), Y.Shafranovich, IETF, October 2005, https://www.ietf.org/rfc/rfc4180.txt. |
1.5 Nomenclature
| AfA PNP | Access for All Personal Needs and Preferences |
| BOM | Byte Order Mark |
| CEDS | Common Education Data Standards |
| CSV | Comma Separated Values |
| GUID | Globally Unique Identifier |
| IETF | Internet Engineering Task Force |
| JSON | JavaScript Object Notation |
| LDAP | Lightweight Directory Access Protocol |
| LMS | Learning Management System |
| LTI | Learning Tools Interoperability |
| NCES | National Center for Educational Statistics |
| OR | OneRoster |
| ORCA | OneRoster Consumer API |
| REST | Representational State Transfer |
| RFC | Request For Comment |
| SIS | Student Information System |
| TLS | Transaction Layer Security |
| UTF | Unicode Transformation Format |
| UUID | Universally Unique Identifier |
2. OneRoster Interoperability Architecture
Like all 1EdTech specifications, the OneRoster specification describes data in motion i.e. the exchange of information achieved using agreed interoperability. For OneRoster the information being exchanged is collated in three groups:
- Class Rosters - the set of people enrolled on a class at a site and for a set period;
- Resources - to identify the set of resources that are required for a class and/or a course;
- Gradebooks - the data is broken into results, lineItems (a set of results) and categories (a set of lineItems).
The underlying model for the OneRoster interoperability is shown schematically in Figure 2.1
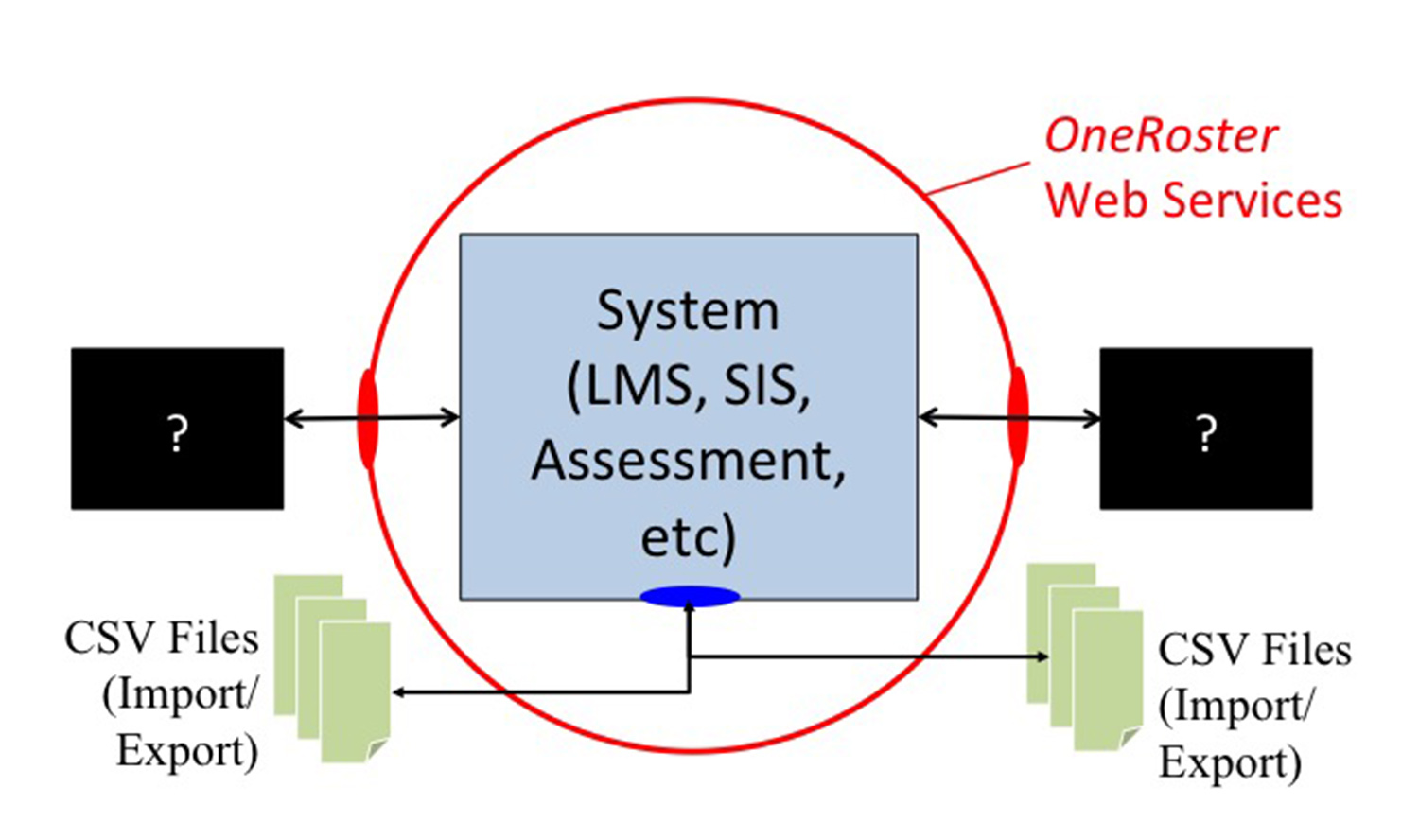
Figure 2.1 - OneRoster Interoperability Architecture.
OneRoster has two modes of data exchange:
- CSV files - in which the data is contained in a set of CSV files that are exchanged as a zip file. The way in which the data is moved from one system to another is not defined and so may vary from implementation to implementation e.g. using FTP, email, etc. A system may provide data import, data export or both import and export. The phrasing of import/export is used because it is unlikely that the internal storage of the data in a system e.g. LMS, SIS, etc. uses the CSV format;
- REST API - in which the exchange is defined as a set of JSON payloads carried in HTTP calls (this is based upon a RESTful exchange model). The REST API has an extensive set of service endpoints that define how that data can be exchanged in real-time. Most of the endpoints allow the reading of data from a service provider but in the case of Gradebook data it is possible for a service provider to write the data to, or delete the data in, a service consumer. The REST API includes support for: the paging of large payloads, sorting of the data in a payload, selecting data according to a set of filtering rule, and specifying the return of just a subset of the full payload.
3. Common REST/CSV Adoption Best Practices
3.1 Identifiers and their Use
3.1.1 Sourced Identifiers
The ‘sourcedId’ attribute is used to provide the unique identification of the associated object between the communicating end-systems. Ideally, these should be globally unique identifiers (the internal format/structure is an implementation dependent issue and NOT constrained to a form of Universal Unique Identifier, UUID). The identifiers MUST not be used as the internal data store keys i.e. a mapping between the identifier and the key should be maintained by an implementation.
Every data object is allocated a unique identifier i.e. its ‘sourcedId’. This identifier must be unique in the context of the two systems that access the object i.e. the identifiers do not have to be globally unique. The end-systems are responsible for maintaining the contextual integrity of these identifiers. The ‘sourcedId’ is not required to have end-system significance except for enabling the associated record to be identified for the processing of the CSV file.
It is the inability to find a record for a given ‘sourcedId’ that is used to define a ‘deleted’ record. Therefore, an end-system should have its own unique key for identifying the associated record. This ensures that the record does not have to be deleted from the end-system to provide consistent interoperability deletion.
If an object has been deleted then the associated 'sourcedId' MUST NOT be reassigned to another object. Therefore, once a 'sourcedId' has been assigned it is permanently allocated to the associated object and so can be used to recover 'deleted' data.
The sourcedId is used as the unique interoperability key. If data is being received from multiple sources e.g. the import and aggregation of many sets of CSV files, then it is possible that the same 'sourcedId' may be used for different objects (each source will have some 'sourcedId' generation/allocation mechanism and so the probability of a clash will depend on the sophistication of those approaches). It is recommended that sytems make use of access control mechanims to minimise accidental data overwriting. For example, in the REST API a HTTP PUT request on an existing object will result in that object being replaced by the new data set. Therefore, a write request should be moderated by a suitable access control mechanism with requests that fail the access control rules returning the HTTP code 403 (forbidden).
3.1.2 Resources VendorId
This should be an identifier that uniquely identifies the vendor. The actual ‘vendorId’ has two components: ‘vnd.****’
The string ‘****” will be assigned by 1EdTech as part of the OneRoster Conformance program.
3.1.3 User Ids
The user class has a number of identifier fields. In keeping with 1EdTech specifications, the preferred practice is for the 'sourcedId' field to be used wherever possible, across all systems. That is to say, the SIS should provide a 'sourcedId' for a user to the LMS. The LMS should provide that same 'sourcedId' for that user to any tools that it launches via LTI, rather than supplying some other identifier. This should be true across all orgs and roles.
However, it is known that at present this isn’t current practice, so other identifiers have been added to the user class to enable migration to best practice.
The 'userId' field is intended as a bridging piece in which any other machine readable 'id' can be stored for a given user. This might be an LTI identifier, or it might be an active directory or LDAP identifier. If LMSs cannot use the 'sourcedIds' for the user when making external calls, then this field can be used instead. In 1.1 support for the assignment of multiple 'userIds' was added in which each identity has an assigned type (there is no predefined vocabulary for this type field and so it is left to local deployments to establish an appropriate vocabulary e.g. LDAP, LTI, etc.).
Also included is a field called 'identifier'. This is purely for humans to use when referring to a particular user for whatever reason. It is not a machine-readable field and should not be processed as anything other than a human readable string.
3.1.4 School and District identifiers
These identifiers are purely for humans to use when referring to a particular instance. These fields are not designed to be machine readable, and should not be processed as anything other than a human readable string.
NCES Identifiers: In the USA, the National Center for Educational Statistics issues identifiers for schools and districts that are to be used when reporting to the NCES. It is considered best practice to use these identifiers in the appropriate orgs to which they belong. For example, a high school record should include the NCES ID for that high school in the human readable 'identifier' field.
Non-US Jurisdictions should agree on a suitable identifier for their region.
3.2 The 'enabledUser' Attribute in the 'Users' Class
This field originates from the 'status' field in OR 1.0. In discussing the 'status' field values in OR 1.0 as they are used in 'users.csv', a problem was identified in that the delta mode submissions carried more information than could be expressed in bulk mode. In delta mode, using the 'status' field, one could distinguish a user as needing to be deleted, as being current and active, and as being current but not active. In bulk mode, there are two states, "the row is present in the csv", which most closely corresponds to the delta status of 'active' and "the row was in a previous submission but is now missing from the CSV", which most closely corresponds to the delta status of 'tobedeleted'. So there is an entire value in field 'status', 'inactive', which cannot be modeled in a bulk transmission in OR 1.0.
Further discussion revealed that the distinction between 'active' and 'tobedeleted' was a concern of the data exchange protocol, whereas the distinction between 'active' and 'inactive' was useful entity data. Further investigation found that the active vs inactive distinction was only ever intended for users.
Given those observations, it was decided to eliminate 'inactive' as a status for all files, and for the Users class, add a new field, 'enabledUser', that expresses the distinction between the OR 1.0 'active' and 'inactive' statuses. In OR 1.1 this fixes the flaw that bulk files cannot express all three states. Now they can, with "row present" and "row missing" being an indication of 'active' vs 'tobedeleted', and, for 'users.csv', the 'enabledUser' field indicating the distinction between OR 1.0's 'active' and 'inactive'.
Since the status field was mandatory in OR 1.0 delta submissions, the 'enabledUser' field mandatory in OR 1.1. The ability to accept and understand the 'inactive' status was mandatory in OR 1.0 as well, so it does not add further constraint to OR 1.1 to require that a processor accept the 'enabledUser' field.
3.3 Status Fields Values Implications
The status field now has permitted values of 'active' and 'tobedeleted' i.e. the 'inactive' token in OR 1.1 has been removed. For backwards compatibility with OR 1.0 the 'inactive' value should be treated as 'tobedeleted'. The following processing rules are to be applied:
- In bulk mode any corresponding type of object that is stored in the database not included in the data being read/imported should have its status set as 'tobedeleted';
- The length of time between the record being set as ‘tobedeleted’ and the actual deletion action is implementation dependent;
- Once an object has been deleted its 'sourcedId' MUST not be re-assigned to another object i.e. a bulk/delta action on that same 'sourcedId' should cause a recovery of the original object (assuming a hard delete has not occurred) or a failure response (if a hard delete has occurred).
The state diagram for the management of records using bulk/delta processing at the service provider is shown in Table 2.1 [OneRoster, 17b].
4. CSV File Handling Best Practices
4.1 File Encoding and File Ordering
The file format for each of the data files is a comma separated values format (CSV) as specified in RFC 4180 [RFC4180] with the extra restriction that carriage-returns are not permitted within a field. Fields containing commas and double-quotes must be enclosed in double-quotes. If double-quotes are used to enclose a field, then a double-quote appearing inside the field must be escaped by preceding it with another double-quote.
The CSV files must be UTF-8 encoded [RFC3629]. Importing processors must tolerate BOM (Byte Order Mark) prefixes and ignore them. In a UTF-8 encoded file with a BOM, the BOM will appear as the 3-byte sequence ‘EF BB BF’ at the beginning of the file. If present, the CSV header will begin at the 4th byte of the file; if not present, the CSV header will begin at the 1st byte of the file.
When the data is exchanged as CSV files, there will be 1-14 CSV files. An exchange MUST include the ‘manifest.csv’ file. The case of when only the ‘manifest.csv’ is supplied is used to denote that no updates occurred. At most, 14 CSV files exchanged i.e. there MUST NOT be more than one of each of the data CSV files. When the set of files are for bulk processing then they must be semantically consistent i.e. every object referenced in a file must also be defined in either the same, or one of the other files in the zip package.
The CSV files will be exchanged as a zip file. The encompassed files must be at the root level i.e. they MUST NOT be contained within an enclosing directory. There is NO constraint on the name of the zip file but it must have a file extension of ‘zip’. The compression must conform to RFC 1951 [RFC1951]. Within the zip file there is NO preferred ordering of the CSV files.
4.2 Exchanging the CSV Files
The CSV files should be exchanged as a zipped file. These files must NOT be encrypted otherwise they will not pass validation: the transport mechanism is responsible for encrypting the data and so protecting the integrity of the CSV files.
The transport mechanism is out the scope of the CSV Binding.
4.3 Round-tripping Between V1.1 and V1.0
It is good best practice to support round-tripping between OneRoster versions without losing data. For example, consider when an organization submits a OR 1.1 CSV file to a OneRoster gateway which sends it on to vendors which support v1.1 in v1.1 format but where it needs to send the data to a vendor which support v1.0 only, it sends it in v1.0 form, but rather than throwing away fields which are not part of the v1.0 specification, these are encoded as metadata fields of the same name.
For example if the v1.1 'users.csv' includes data for the grade column convert that to a ‘metadata.orv1p1.grade’ column in the equivalent ORv1.0 CSV. While the 1.0 conformant system may not understand the semantics of grade, it may support the display of the metadata fields, including grade to end users who need the grade information, and it may also have use where a system allows search filters include meta-data fields make use of the grade information by filtering on’ metadata.orv1p1.grade’.
When converting the v1.0 CSV to v1.1 then ALL the columns with ‘metadata.***’ should be placed as the final set of columns (the order is NOT significant).
4.4 Ensuring Semantic Consistency
For 'bulk' exchange the set of CSV files MUST be semantically complete i.e. if a 'sourcedId' reference for an object is used in one of the CSV files then that object MUST be defined somewhere in the set of CSV files (it may be the CSV file in which the reference occurs). The data models for the CSV files means that the following groups of files may be exchanged with the accompanying constraints of:
- 'academicSessions.csv' - this file may contain references to other academicSessions and so ALL such definitions must be contained within the same file. This CSV file may be exchanged independently of other files;
- 'categories.csv' - this file contains no references to other files and so it may be exchanged independently of other files;
- 'classes.csv' - this file MUST contain references to the relevant academisSession, course and organization objects. Therefore it must be accompanied with the 'academicSessions.csv', 'courses.csv' and 'orgs.csv' files;
- 'classResources.csv' - this file MUST contain references to the relevant academisSession, class, organization and resource objects. Therefore it must be accompanied with the 'academicSessions.csv', 'classes.csv', 'orgs.csv' and 'resources.csv' files;
- 'courseResources.csv' - this file MUST contain references to the relevant academisSession, course, organization and resource objects. Therefore it must be accompanied with the 'academicSessions.csv', 'courses.csv', 'orgs.csv' and 'resources.csv' files;
- 'demographics.csv' - this file MUST contain references to the relevant organization and user objects. Therefore it must be accompanied with the 'orgs.csv' and 'users.csv' files;
- 'enrollments.csv' - ths file MUST contain refernces to academicSession, class, course, organization and user objects. Therefore it must be accompanied with the 'academicSessions.csv', 'classes.csv', 'courses.csv', 'orgs.csv' and 'users.csv' files;
- 'lineItems.csv' - ths file MUST contain refernces to academicSession, categories, class, course, organization and user objects. Therefore it must be accompanied with the 'academicSessions.csv', 'categories.csv', 'classes.csv', 'courses.csv', 'orgs.csv' and 'users.csv' files;
- 'courses.csv' - this file MUST contain references to the associated organization and may contain references to academicSession objects. Therefore it must be exchanged with an 'orgs.csv' file and may require an 'academicSessions.csv' file;
- 'orgs.csv' - this file may contain references to other organizations and so ALL such definitions must be contained within the same file. This CSV file may be exchanged independently of other files;
- 'resources.csv' - this file contains no references to other files and so it may be exchanged independently of other files;
- 'results.csv' - ths file MUST contain refernces to academicSession, categories, class, course, lineItem, organization and user objects. Therefore it must be accompanied with the 'academicSessions.csv', 'categories.csv', 'classes.csv', 'courses.csv', 'lineItem.csv', 'orgs.csv' and 'users.csv' files;
- 'users.csv' - this file MUST contain references to the associated organization and may contain references to other user objects (whose definition must be contained within the same file). Therefore it must be exchanged with an 'orgs.csv' file.
The full details of this grouping of files is available in the OneRoster CSV definition [OneRoster, 17b]. However, it should be noted that an implementation may require/supply more than the minimum set of semantically consistent files. For example is not uncommon to encounter implementations to require/provide the following sets of files
- For Rostering exchange - 'academicSessions.csv', 'classes.csv', 'courses.csv', 'enrollments.csv', 'orgs.csv' and 'users.csv' files;
- For Resource exchange - 'academicSessions.csv', 'classes.csv', 'classResources.csv', 'courseResources.csv', 'courses.csv', 'enrollments.csv', 'orgs.csv' and 'resources.csv', 'users.csv' files;
- For Gradebook exchange - 'academicSessions.csv', 'categories.csv', 'classes.csv', 'courses.csv', 'enrollments.csv', 'lineItems.csv', 'orgs.csv', 'results.csv' and 'users.csv' files;
4.5 Extending the Data Model for the CSV Files
4.5.1 Extending the Vocabularies
The enumerated vocabularies MUST NOT be extended.
Open vocabularies MAY be extended. These extensions should take the form of a URI so that the creator of the term is also supplied.
4.5.2 Extending the Data Model
For CSV exchange, the data model can only be extended by adding new columns to the end of the defined set of columns. A suitable naming convention should be used for the new header names. An example is:
metadata.[orglabel].[namepart]
Where:
- ‘metadata’ is the initial set of characters for all extensions;
- [orglabel] is the label used to identify the organization that has created the extension. In the case of an extension from 1EdTech this field will be empty and one of the delimiters removed;
- [namepart] the unique header name part allocated by the organization for the data model.
Examples are: 'metadata.hmh.homeemail', 'metadata.pearson.namesuffix', etc.
4.6 Suggested Extension Fields
4.6.1 'courses.csv' Data Model
Suggested metadata fields for the ‘courses.csv’ file are:
| Field Header | Required | Format | Description |
|---|---|---|---|
| metadata.duration | No | String | Description of how long the course runs for (e.g. two weeks, one semester). |
4.6.2 'orgs.csv' Data Model
Suggested metadata fields for the ‘orgs.csv’ file are:
| Field Header | Required | Format | Description |
|---|---|---|---|
| metadata.classification | No | String | “charter” | “private” | “public” |
| metadata.gender | No | String | “female” | “male” | “mixed” |
| metadata.boarding | No | Boolean | “true” if school is boarding school. |
| metadata.address1 | No | String | First line of the organization’s free format address e.g. “80 Iron Point Circle”. |
| metadata.address2 | No | String | Second line of the organization’s free format address e.g. “Dept. 2100”. |
| metadata.city | No | String | The city in which the organization operates e.g. Bismarck. |
| metadata.state | No | String | Postal abbreviation for the state/province in which the organization operates, e.g. “ND”. The vocabulary for U.S. addresses: https://ceds.ed.gov/CEDSElementDetails.aspx?TermxTopicId=20837. The vocabulary for Canadian addresses: https://www.canadapost.ca/tools/pg/manual/PGaddress-e.asp?ecid=murl10006450#1442218. |
| metadata.postCode | No | String | The zip/postal code of the organization address, e.g. (for U.S. addresses) “91311” or “91311-5349”, (for Canadian addresses) “K1A 0B1”. |
| metadata.country | No | String | The country in which the organization operates. Use the CEDS Vocabulary at: https://ceds.ed.gov/CEDSElementDetails.aspx?TermxTopicId=20002. |
4.6.3 'users.csv' Data Model
Suggested metadata fields for the ‘users.csv’ file are:
| Field Header | Required | Format | Description |
|---|---|---|---|
| metadata.pnpfileurl | No | String | This is the URL for the user's Access for All Personal Needs and Preferences file. This file defines the configuration settings for the accessibility features for any computer systems to be used by the user. The contents of the file identified by this URL are as defined in the associated 1EdTech AfA PNP 2.0 specification [AfA PNP, 10]. |
5. REST-based Exchanges Best Practices
5.1 Compatibility of the REST API between Versions 1.0 and 1.1
A system that is certified as OneRoster 1.0 must be separately certified for OneRoster 1.1 compliance. Updating a OR 1.0 system for OR 1.1 conformance testing requires the following changes:
- The base URL must be changed from '/learningdata/v1' to '/ims/oneroster/v1p1';
- The redefinition of the required endpoints (classified in the three groups of rostering, resources and gradebook) should be inspected (in OR 1.0 there was no subgrouping and support for only a subset of the endpoints is required). A set of new endpoints have been added;
- The detailed data models must be investigated. A number of optional additional attributes have been made to the data models, some attributes in the data models have been renamed and some have had their types refined. These have created significant differences in some of the JSON payloads;
- In the case of the Gradebook endpoints for data writing (using the HTTP PUT verbs) the payloads must be signed using an extra OAuth parameter.
5.2 Authentication
OneRoster 1.1 and OneRoster1.0 require the same message signing mechanism for conformance i.e. OAuth 1.0a with HMAC-SHA1 over TLS 1.2. OneRoster 1.1 also permits:
- Support for HMAC-SHA2 (256) as opposed to HMAC-SHA1 with TLS 1.2;
- The use of OAuth 2 Bearer Tokens as defined in RFC 6750 for authorization with TLS 1.2 for message encryption.
While ALL implementations must support OAuth 1.0a with HMAC-SHA1 over TLS 1.2 for conformance it is STRONGLY RECOMMENDED that HMAC-SHA256 is used (optional conformance for this is also available). For OR 1.2 the ONLY permitted authentication mechanism will be OAuth 2 Bearer Tokens (1EdTech is aligning all authentication mechanisms to be based upon OAuth 2).
5.3 Read, Write, Delete Choreography Implications
In OR 1.1, Read, Write and Delete choreography is only an issue for the Gradebook services endpoints. The set of Read endpoints provide the data 'pull' capability whereas the Write/Delete provide the 'push' capability. The specification does not prescribe any specific choreography. A choreography is defined to realise a specific workflow but the OR specification is designed to enable a wide range of workflows. The OR 1.1 Specification [OneRoster, 17a] provides a simple state diagram for the pull and push endpoints. Typically, a workflow will require a mix of the 'pulll' and 'push' endpoints. Some issues to be considered when realising a workfkow are:
- The Write and Delete endpoints can only operate on a single object at a time. Therefore, the REST API should not be used for large-scale deletions and data creation;
- When an object has been 'deleted' the 'sourcedId' MUST not be reallocated and a Read request on that 'sourcedId' MUST result in a read failure (with a HTTP 404 code);
- Care should be taken to avoid overlapping Read/Write requests at a Provider i.e. a Provider should not issue a Write request to a Consumer that has an incomplete Read request being processed by the Provider;
- Care should be taken to avoid overlapping Read/Write requests at a Consumer i.e. a Consumer should ensure that a received Write/Delete request does not conflict with a concurrent and incomplete Read request. The manner in which the conflict is avoided is implementation dependent.
5.4 Matching End-to-End Service Capabilities
The available certifications for a OR 1.1 REST implementation is summarised in Table 5.1.
| Functional Mode (at least one must be supported) |
REST API | |||
|---|---|---|---|---|
| Provider | Consumer | |||
| Core | Other | Core | Other | |
| Rostering | Required | Optional | Required | Optional |
| Resources | Required | Optional | Required | Optional |
| Gradebooks | Required (Pull or Push) | Optional | Required (Pull or Push) | Optional |
Therefore, when matching whether or not two certified OR 1.1 REST systems can exchange data the following rules should be applied:
- A Provider/Consumer pair WILL have core endpoint interoperability if they support the same mode(s) pairings of operation i.e. rostering/rostering, resources/resources, gradebook(pull)/gradebook(pull) and gradebook(push)/gradebook(push) pairings;
- For a common pairing there will also be interoperability for ANY of the optional endpoints that are supported by both the provider/consumer;
- Only the mandatory data attributes are guaranteed to be exchanged. Different systems will support different combinations of the optional data attributes and so a mapping between the capabilities of the provider/consumer must be undertaken (this information is not available from the 1EdTech certification report or the 1EdTech product database);
- ALL REST implementations MUST support the OAuth 1.0a/SHA1 message signing. Support for the other authentication mechanisms (OAuth 1.0a/SHA256 and Oauth 2 Bearer Token) is optional and so can ONLY be used if both the provider/consumer have been certified as supporting that mechanism.
5.5 Gradebook Exchanges
5.5.1 Assignment Grade Transfer Usecase
Assignment-level grade transfer is important for K-12 districts and schools that use SIS technology for state reporting requirements. Typically, the LMS serves as a system of record for assignment data and facilitates the assignment grade transfer on an on-demand or scheduled basis. The SIS provider acts as a grade data consumer and exposes endpoints to accept the assignment grade data from the LMS. OneRoster specification v1.1 gradebook services provides a set of specific RESTful endpoints to facilitate an assignment grade data transfer.
OneRoster specification v1.1 gradebook services recommends a set of specific RESTful endpoints to facilitate an assignment grade data transfer.
In a typical assignment grade data transfer implementation, the LMS serves as a system of origin for 'lineItem' and 'result' objects. The majority of SIS gradebooks require an end user to segregate 'lineItem' objects by 'lineItem' grading categories such as “homework”, “quizzes” or “essays”. Best practice is for the SIS provider to expose 'lineItem' categories available for the end user in the SIS gradebook via the '\categories' endpoint. The LMS provider will request categories on an on-demand or scheduled basis to allow an end user to maintain SIS LineItem category nomenclature and sourcedIds in the LMS.
Commonly, the LMS should provide the end user with a utility to request the transfer of assignment grades to an SIS gradebook on an on-demand or scheduled basis. When a grade transfer is requested, the LMS assembles the LineItem and/or LineItem Result dataset and pushes it to the SIS gradebook. The LMS uses putLineItem and putResult RESTful endpoints to insert assignment and assignment grade objects into the SIS gradebook.
The following use cases are commonly accepted in the industry:
Step 1: LMS imports LineItem Categories from SIS via GET Categories service call:-
- SIS generally supplies:-
- sourcedId (use UUID or GUID to avoid any data collusion)
- category title
- category status
- Metadata Optional: link to course, class, teacher user or gradebook via corresponding sourcedId (allows the LMS provider to set proper permissions around access to grading categories in LMS course gradebook)
- LMS generally imports LineItem Categories on an on-demand or scheduled basis:-
- request LineItem Categories from the SIS via the getCategories endpoint
- create SIS LineItem Categories in the LMS
- allow the end user to associate line items with grading categories imported from the SIS
Step 2: LMS generally creates LineItem object in the SIS via PUT LineItem service call:-
- Dataset commonly required by the SIS:-
- LineItem sourcedId (use UUID or GUID to avoid any data collision)
- Title
- dueDate
- Class
- Category
- Result Value
Step 3: LMS generally creates Result object in SIS via PUT Result service call by providing GUID or UUID for each result record;
Step 4: LMS generally replaces LineItem object in SIS via PUT LineItem service call:-
- SIS to allow LMS:-
- Replace all data elements in the existing lineitem records with new values
- Override lineItem data element values multiple times
- Restore a lineItem record after it has been soft deleted from the SIS e.g. when the end user accidentally deletes a lineItem in the SIS but the lineItem is still active in the LMS
Step 5: LMS generally replaces Result object in SIS via PUT Result service call:-
- SIS to allow LMS:-
- Override Line Item Result data element values multiple times
- Restore a Result object with PUT Result service call after it has been soft deleted from the SIS e.g when the end user accidentally deletes a line item result in the SIS but the line item is still an active result in the LMS
Step 6: LMS generally deletes LineItem object in SIS via DELETE LineItem service call:-
- SIS to update Line Item status to “tobedeleted” (for soft delete)
- SIS to remove Line Item from the SIS gradebook (for hard delete);
Step 7: LMS generally deletes Result object in SIS via DELETE Result service call:-
- SIS to update Result status for result record that matches provided result sourcedId to “tobedeleted” status (for soft delete)
- SIS to permanently remove Result record that matches provided result sourcedId from SIS gradebook (for hard delete). It should be noted that OneRster oes NOT allow the sourcedId of the result record that was previously deleted to be reused.
5.5.2 Multiple Gradebook Data Providers and SourcedId Data Collusion Usecase
In the cases when a gradebook data consumer accepts lineItem and result data from multiple gradebook data providers, precautions should be made to avoid accidental overrides of gradebook data lineItem and result records. PUT/DELETE service calls should be executed using UUID or GUID for all records 'sourcedId' values. Gradebook service data consumers may want to uniquely identify requests coming from different data providers to insure gradebook data integrity persists.
5.5.3 Grading Category interpretations in LMS and SIS Usecase
Depending on the learning technology, a grading category object can have multiple data models. Grading categories are typically used to group the learning objects together according to a specific topic or value. Grading categories also help teachers weigh groups of learning activities and calculate how much each topic contributes toward the course total grade. In the SIS, grading categories could be represented as a grading category library set up by the system administrator, a collection of custom grading categories set up by a teacher, a collection of grading categories available as system defaults, or a combination of all options.
Grading categories could be specific to a user, class, course, school, or district. The SIS or LMS could be a system of origin for grading categories; in a typical setup, the SIS provider owns the grading categories, and the LMS provider imports grading categories on regular basis. After the grading categories are imported into the LMS, teachers can start using grading categories in their respective courses. Ideally the grading categories created for a specific class or by a specific user have the class and user sourcedId associated with them, which allows the LMS to properly map grading categories inside the courses or classes and avoid placing any manual data configuration burden on the end user.
5.6 Extending the REST API
By definition the creation and use of extensions creates features that are not interoperable. Extensions must NOT be used to replace the supported functionality. Extensions should be created as a last resort. There are two ways in which the REST API can be extended:
- Adding endpoints - new endpoints can be defined and added to the API. Such endpoints should follow the pattern of the established endpoints and the associated JSON payloads should be well defined and, if required, use the same data model extension method as used for the other endpoints;
- Adding to the data model - the data model includes a 'metadata' class that MUST be used when new attributes are to be added to a JSON payload (the use of this class is explained in the OneRoster 1.1 specification [OneRoster, 17a]. The addition of attributes into a JSON payload using any other technique is PROHIBITED.
It is recommended that organizations that wish to create extensions contact 1EdTech (Lisa Mattson, 1EdTech COO).
6. Realising the Usecases
Some of the use-cases that can be supported using OR 1.1 are:
- Establishing and maintaining a district repository for K-12 Information;
- Making roster information available;
- Identification of Resource Allocation;
- SIS/LMS exchange of gradebook information;
- Real-time bulk exchange of OneRoster information;
- Batch bulk exchange of OneRoster information.
6.1 Establishing and Maintaining a District Repository for K-12 Information
Large-scale data aggregation should be realised using CSV Import. The manner in which the zip file data is made available for import is implementation dependent i.e. it is NOT defined as part of the OR specification. The supplier of the CSV files is responsible for assigning/identifying each record with a 'sourcedId'. Therefore, there may be 'sourcedId' clashes when zip files are supplied from more than one supplier/source. Import of a set of CSV files using the bulk mode is used to establish/redefine the data set whereas the delta mode is used to update the data set. The aggregation of data from multiple sources should be carefully managed to ensure that data separation/integrity is managed appropriately.
6.2 Making Roster Information Available
Rostering data can be made available through the REST API or as a set of exported CSV files. Exported CSV files should be used when real-time availability is not required and/or when the size of the data-set is excessive i.e. gigabytes. Once the zip file containing the CSV files has been created the method of exchanging the file is implementation dependent. The REST API makes collections of data sets available depending on the endpoint i.e. all of the 'user' objects are available from one endpoint, a separate endpoint is used for obtaining all of the 'course' objects, etc. Therefore, obtaining a mixed set of objects requires the use of more than one endpoint (the corresponding choreography is implementation dependent). The REST API permits reading of the roster data ONLY i.e. the consumer MUST issue a read request to the provider.
6.3 Identification of Resource Allocation
A new feature in OR 1.1 is the ability to identify the set of resources that are required for a class and/or course. This identification uses a GUID for the resource i.e. it does not include the actual resource (one way of obtaining the resource is to use an 1EdTech Common Cartridge/Thin Common Cartridge which provides the access to the resource via an identifier). The resource identification can be supplied using either CSV-based or REST API-based exchange.
6.4 SIS/LMS Exchange of Gradebook Information
A key new feature in OR 1.1. is extensive support for the exchange of gradebook information. Both CSV-based and REST API-based approaches are available. In the case of the REST API both 'push' and 'pull' endpoints are available. In many implementations there is a choreography using both push and pull approaches (see Section 5.5 for a detailed explanation of how this can be achieved).
6.5 Real-time Bulk Exchange of OneRoster Information
This is achieved using the REST API with the consumer system reading the data sets from the provider. The consumer must issue a set of read requests on each of the collections that are required for the batch exchange. The REST API defines a pagination mechanism to ensure that the consumer can control the amount of data that it will receive in each response payload. The consumer will issue a sequence of requests until all of the collection has been received. The next collection can then be requested. The order of the reading of the collections is determined by the consumer.
6.6 Batch Bulk Exchange of OneRoster Information
This is achieved using CSV export/import. The source system creates the set of CSV files using OR 1.1 CSV export to create the new zip file. This file is now transported to the receiving system (the method of transport is implementation dependent e.g. using secure FTP, etc.). The receiving sytem must now import the CSV file set using OR 1.1 CSV import capability. If errors are detected during the import then a manual recovery mechanism must be used.
Appendix A - Key Terms and Definitions
| Bulk-based Exchange | This is the exchange of data in which all of the currently stored data is to be replaced by the newly supplied data set. The payload/csv values of the 'status' and 'dateLastModified' fields must be empty. Upon receipt of such records all of the included records are set with the 'status=active' and 'dateLastModified="...date/time of the import..."'. Records that exist in the data store but which are not contained within the new data set must have their status set as 'tobedeleted'. |
| Conformance and Certification | Conformance is the process by which 1EdTech determines whether or not an implementation is compliant to a specification. 1EdTech defines the conformance process for each specification that it publishes as part of the specification development process. All implementations that pass the 1EdTech conformance for a specifictaion will be certified as compliant i.e. 1EdTech will award a certification number for that product. Many vendors claim that their products are compliant to a specification but this should be confirmed by checking they are certified i.e. they have a certification number and the product is listed under the 1EdTech Certified Product Directory. |
| CSV-based Exchange | The data is contained in a set of CSV files that are exchanged as a zip file. The way in which the data is moved from one system to another is not defined as so may vary from implementation to implementation e.g. using FTP, email, etc. A system may provide data import, data export or both import and export. The phrasing of import/export is used because it is unlikely that the internal storage of the data in a system e.g. LMS, SIS, etc. uses the CSV format. |
| CSV Import | The process by which the set of CSV files, a zip file, are loaded into a system. An importing system is expected to validate the set of files syntactically and semantically and must be capable of detecting any errors. The subsequent handling of any files found to contain errors is undefined by the specification. |
| CSV Export | The process by which a system creates a set of OneRoster CSV files to be used by some other external system(s). An exporting system must create a semantically consistent set of files determined by the nature of the file e.g. 'bulk' or 'delta'. |
| CSV Validator | This is the online 1EdTech conformance test system that is used to determine if a set of CSV files is compliant to the OneRoster 1.0 or 1.1 specifications. This validator is ONLY available to 1EdTech Members and can be accessed at: http://onerostervalidator.imsglobal.org:8080/oneroster-server-cts-webapp/instructions |
| CSV Reference Test Set | This is the set of test CSV files produced by 1EdTech to support conformance testing of systems that claim CSV import functionality support. For OR 1.1, this test set, available through the OneRoster Conformance web-pages, consists of many zip files some of which contain known errors. As part of conformance testing for CSV import, a system must demonstrate that it can correctly process each of the zipped CSV file sets and produce a reprt/log that indicates the result of the import processing. A system MUST detect any errors in the syntax and/or semantics of the data in the CSV files but the subsequent processing of that data is implementation dependent i.e. a system is not required to reject data that has errors (this allows for market differentiation in how systems handle error recovery). |
| Data Aggregator | A data aggregator is a system that collects data from one or more systems, processes this information and then makes it available to other systems. OneRoster data aggregators should use OneRoster for the collection and forwarding of the data. Proprietary interfaces could be used, for input or output, but this creates a proprietary gateway approach to the data aggregation. A typical data aggregator would make use of OR CSV-based data importing with the data made available to other systems using the OR REST API. |
| Delta-based Exchange | This is the exchange of data in which all of the currently stored data is to be updated by the newly supplied data set. The payload/CSV values of the 'status' and 'dateLastModified' fields must be set. Upon receipt of such records all of the stored records are updated with the new 'status' and 'dateLastModified' values as is data itself. Records that exist in the data store but which are not in the new data set are unchanged. |
| Gradebook 'Pull' Endpoints | This is the set of endpoints that enable a Service Consumer to read (pull) the data from the Service Provider. This is the 'readAllCategories', 'readCategory', 'readAllLineItems', 'readLineItem', 'readAllResults', 'readResult' 'getLineItemsForClass', 'getResultsForClass', 'getResultsForLineItemForClass' and 'getResultsForStudentForClass' set of endpoints. |
| Gradebook 'Push' Endpoints | This is the set of endpoints that enable a Service Provider to manage (push) the data to/in a Service Consumer. This is the 'putCategory', 'deleteCategory', 'putLineItem', 'deleteLineItem', 'putResult' and 'deleteResult' set of endpoints. The 'push' endpoints operate on a single record ONLY. |
| OneRoster Consumer API (ORCA) | This is the reference implementation for the OR Consumer API i.e. the code base for realising the OR consumer funcionality. This can be created by using the OR 1.1 OpenAPI description file and using the Swagger toolkit to create the code library (Swagger supports a wide range of code-bases). |
| OneRoster Gradebook | The collection of the exchange features in OR that are responsible for gradebook information. Therefore this is the collection of the 'categories.csv', 'lineItems.csv' and 'results.csv' and/or the endpoints for 'categories', 'results' and 'lineItems'. |
| OneRoster Resources | The collection of the exchange features in OR that are responsible for resources information. Therefore this is the collection of the 'classResources.csv', 'courseResources.csv' and 'resources.csv' files and/or the endpoints for 'resources'. |
| OneRoster Rostering | The collection of the exchange features in OR that are responsible for achieving rostering. Therefore this is the collection of the 'academicSessions.csv', 'classes.csv', 'courses.csv', 'demographics.csv', 'enrollments.csv', 'orgs.csv' and 'users.csv' files and/or the endpoints for 'academicSessions', 'classes', 'courses', 'demographics', 'enrollments', 'gradingPeriods', 'orgs', schools', 'students', 'teachers', 'terms' and 'users'. |
| OpenAPI/Swagger Definition | The OpenAPI specification is a vendor neutral API Description Format based on the Swagger Specification. This specification is developed and supported by the OpenAPI Initiative (OAI): this is an open governance structure under the Linux Foundation. 1EdTech use the OpenAPI format, available in both JSON and YAML forms, to provide a computer-readable form of the OneRoster 1.1 REST API. |
| REST API-based Exchange | The exchange is defined as a set of JSON payloads carried in HTTP calls (this is based upon a RESTful exchange model). The REST API has an extensive set of service endpoints that define how that data can be exchanged in real-time. Most of the endpoints allow the reading of data from a service provider but in the case of Gradebook data it is possible for a service provider to write the data to, or delete the data in, a service consumer. The REST API includes support for: the paging of large payloads, sorting of the data in a payload, selecting data according to a set of filtering rule, and specifying the return of just a subset of the full payload. |
| Service Consumer | This is an implementation that acts as a OneRoster client i.e. it is capable of issuing the appropriate read requests and receiving the corresponding responses from service providers and/or can respond to the write/delete requests that are issued by a service provider. |
| Service Consumer/Client Conformance Test System | These are the test systems that are used to determine if a service consumer is compliant to the OneRoster 1.1 specification. There are two service consumer conformance test systems: (a) one to check that a service consumer correctly issues the requests (pull/read) to a service provider; and (b) one to confirm that the service consumer correctly responds to write/delete (push) requests. The latter is only required for service consumers that support the 'push' Gradebook services. |
| Service Provider | A Service Provider is a OneRoster compliant system that makes data available to data consumers. Most of this data is supplied via read requests that are issued to the Service Provider by the data consumer i.e. the consumer 'pulls' the data from the Service Provider. In the case of Gradebook the Service Provider can also 'push' the data into the data consumer using a HTTP PUT request. The data is always supplied to the consumer as a JSON payload. |
| Service Provider Conformance Test System | These are the test systems that are used to determine if a service provider is compliant to the OneRoster 1.1 specification. There are two service provider conformance test systems: (a) one to check that a service provider correctly responds to requests (pull/read) received from a service consumer; and (b) one to confirm that the service provider issues correctly formed write/delete (push) requests. The latter is only required for service providers that support the 'push' Gradebook services. |
| SourcedId | Each object must have a unique identifier that is used by the communicating OneRoster end-systems to accurately identify the object. In OneRoster this identifier is called the object's 'sourcedId'. This identifier should NOT be used as the primary key for the local storage of the data i.e. the end-systems should maintain a local mapping between the 'sourcedId' and the corresponding database key. Instead this identifier is ONLY used for the interoperability exchange. While it is strongly recommended that these identifiers are globally unique (there is no requirement to be realised as a UUID) the minimum constraint is that they are unique between the set of communicating OneRoster systems. |
About this Document
List of Contributors
The following individuals contributed to the development of this document:
Revision History
1EdTech Consortium, Inc. ("1EdTech") is publishing the information contained in this document ("Specification") for purposes of scientific, experimental, and scholarly collaboration only.
1EdTech makes no warranty or representation regarding the accuracy or completeness of the Specification.
This material is provided on an "As Is" and "As Available" basis.
The Specification is at all times subject to change and revision without notice.
It is your sole responsibility to evaluate the usefulness, accuracy, and completeness of the Specification as it relates to you.
1EdTech would appreciate receiving your comments and suggestions.
Please contact 1EdTech through our website at http://www.imsglobal.org.
Please refer to Document Name: 1EdTech OneRoster® 1.1 Best Practices and Implementation Guide
Candidate Final Specification v1.0
Date: 17th April, 2017
This page contains trademarks of the 1EdTech Consortium including the 1EdTech Logos, Learning Tools Interoperability® (LTI®), Accessible Portable Item Protocol® (APIP®), Question and Test Interoperability® (QTI®), Common Cartridge® (CC®), AccessForAll™, OneRoster®, Caliper Analytics™ and SensorAPI™. For more information on the 1EdTech trademark usage policy see trademark policy page
© 2001-2017 1EdTech Consortium Inc. All Rights Reserved. Privacy Policy
