 |
1EdTech Digital Repositories Interoperability - Core Functions Information Model Version 1.0 Final Specification |
Copyright © 2003 1EdTech Consortium, Inc. All Rights Reserved.
The 1EdTech Logo is a trademark of 1EdTech Consortium, Inc.
Document Name: 1EdTech Digital Repositories Interoperability - Core Functions Information Model
Revision: 13 January 2003
IPR and Distribution Notices
Recipients of this document are requested to submit, with their comments, notification of any relevant patent claims or other intellectual property rights of which they may be aware that might be infringed by any implementation of the specification set forth in this document, and to provide supporting documentation.
1EdTech takes no position regarding the validity or scope of any intellectual property or other rights that might be claimed to pertain to the implementation or use of the technology described in this document or the extent to which any license under such rights might or might not be available; neither does it represent that it has made any effort to identify any such rights. Information on 1EdTech's procedures with respect to rights in 1EdTech specifications can be found at the 1EdTech Intellectual Property Rights web page: http://www.imsglobal.org/ipr/imsipr_policyFinal.pdf.
Copyright © 2003 1EdTech Consortium. All Rights Reserved.
Permission is granted to all parties to use excerpts from this document as needed in producing requests for proposals.
Use of this specification to develop products or services is governed by the license with 1EdTech found on the 1EdTech website: http://www.imsglobal.org/license.html.
The limited permissions granted above are perpetual and will not be revoked by 1EdTech or its successors or assigns.
THIS SPECIFICATION IS BEING OFFERED WITHOUT ANY WARRANTY WHATSOEVER, AND IN PARTICULAR, ANY WARRANTY OF NONINFRINGEMENT IS EXPRESSLY DISCLAIMED. ANY USE OF THIS SPECIFICATION SHALL BE MADE ENTIRELY AT THE IMPLEMENTER'S OWN RISK, AND NEITHER THE CONSORTIUM, NOR ANY OF ITS MEMBERS OR SUBMITTERS, SHALL HAVE ANY LIABILITY WHATSOEVER TO ANY IMPLEMENTER OR THIRD PARTY FOR ANY DAMAGES OF ANY NATURE WHATSOEVER, DIRECTLY OR INDIRECTLY, ARISING FROM THE USE OF THIS SPECIFICATION.
Table of Contents
1. Introduction
1.1 Nomenclature
1.2 References
2. Functional Architecture
3. Reference Model
3.1 Search/Expose
3.1.1 Recommendations for Query Language
3.2 Gather/Expose
3.2.1 Recommendations for "Pull" Gather
3.2.2 Recommendations for "Push" Gather
3.3 Alert/Expose
3.4 Submit/Store
3.4.1 Submit
3.4.2 Store
3.5 Request/Deliver
3.5.1 Exclusions from Scope
3.5.2 Request/Deliver Mechanism
4. General Messaging Model
4.1 Open Issues
5. High Level Overview of Use Cases for a Learning Repository
5.1 Actors
5.2 Use Cases
5.2.1 Create and Modify Resources
5.2.2 Discover Resources
5.2.3 Notification of Modification of Resources
About This Document
List of Contributors
Revision History
Index
1. Introduction
This document constitutes the Information Model for Phase 1 of the 1EdTech Digital Repositories Interoperability (DRI) Specification. The purpose of this specification is to provide recommendations for the interoperation of the most common repository functions. These recommendations should be implementable across services to enable them to present a common interface. This specification is intended to utilize schemas already defined elsewhere (e.g., 1EdTech Meta-Data and Content Packaging), rather than attempt to introduce any new schema.
On the broadest level, this specification defines digital repositories as being any collection of resources that are accessible via a network without prior knowledge of the structure of the collection. Repositories may hold actual assets or the meta-data that describe assets. The assets and their meta-data do not need to be held in the same repository.
This document begins by describing the scope that the 1EdTech DRI Project Group agreed upon for Phase 1 of the specification. Section 2 specifies the core functional interactions between the Mediation and Provision layers of the DRI Functional Architecture. These core functions are:
Note: Alert/Expose is identified as a key function that will need to be addressed in a later DRI specification.
This specification acknowledges that a wide range of content formats, implemented systems, technologies, and established practices already exist in the area of digital repositories. Consequently, its recommendations consistently acknowledge two generalized implementation scenarios, or two different repository types:
- Systems reflecting established practice (e.g., that utilize Z39.50) for repository interoperability.
- Repositories that are able to implement the XQuery and SOAP-based recommendations as put forward in this specification.
The second repository type or scenario defines repository interoperability very specifically in terms of the full implementation of the core functions and functional architecture, as outlined in this specification. In concise terms, it is an implementation of a collection of resources capable of exposing meta-data to resource utilizers for the purposes of searching, gathering, storing, and delivering assets.
Section 3 defines a general reference model, which captures all instances of possible implementations, such as:
- A user searching a repository directly.
- A user conducting a search across repositories via a Search Gateway intermediary (acting as a translator).
- A user conducting a search across repositories via a Harvest intermediary (acting as an aggregator).
While Z39.50 is assumed for searching systems such as digital libraries, XQuery is recommended as the preferred query mechanism for XML-based learning object repositories. SOAP with attachments is proposed as the protocol for messaging associated with core function implementation.
Section 4 outlines the message structure for each of the core functions addressed.
Section 5 outlines the use cases which have informed the discussion and development of this specification.
1.1 Nomenclature
1.2 References
2. Functional Architecture
The diagram in Figure 2.1 below depicts the DRI functional architecture. The interactions are shown by the red (solid) lines. The diagram maps out three entity types that define the space where e-learning, digital repositories, and Information Services interact, and which provide a context for exploration of the problem space.
- Roles (e.g., Learner, Creator, Infoseeker, Agent)
- Functional Components for Resource Utilizers, Repositories, Access Management, and Procurement Services
- Services, such as Registries and Directories (not part of the DRI Phase 1 scope)
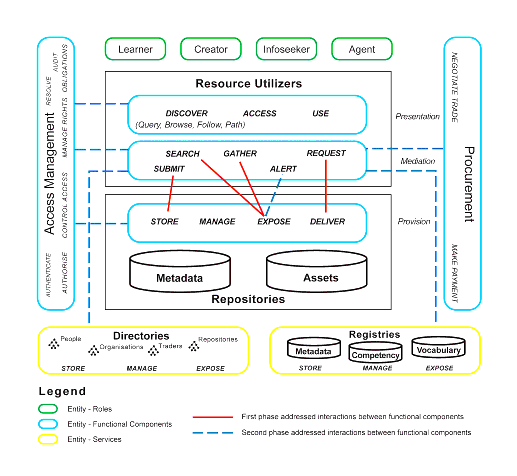
The solid red lines, between a number of functions between Resource Utilizers and Repositories, indicate the interactions between core functional components that support interoperability, including:
Note: ALERT is a core function, but is not addressed within this version of the DRI specification.
The DRI Project Group is focusing on these core interoperability functions within the functional architecture (see Figure 2.2).
3. Reference Model
The diagram in Figure 3.1 provides a simplified systems view of the digital repository domain with the components embodying the core functions identified in Figure 2.2. There are two types of repositories represented in Figure 3.1:
- Systems reflecting established practice (e.g., utilizing Z39.50) for repository interoperability.
- Repositories that are able to implement the XQuery and SOAP-based recommendations, as put forward in this specification.
Section 2 (Functional Architecture) described four roles played by users of a digital repository: Creator, Learner, Infoseeker, and Agent. Figure 3.1 illustrates users playing the first three of these roles and the typical software applications with which they interact. The Agent, LMS, LCMS, and Search Portal applications play the role of Access Components.

The goal of this specification is to enable widespread access to content in repositories of both types in the context of e-learning by applications such as Learning Management Systems (LMS), Learning Content Management Systems (LCMS), and Search Portals (e.g., in library search systems) as shown in the reference model in Figure 3.1. These software applications are used as common examples from the e-learning industry and there may be other applications.
Finding content, when there are multiple repositories of content to be searched, is a complex problem. The problem is further aggravated when the repositories have heterogeneous representations of meta-data and heterogeneous access methods. The reference model introduces an optional intermediary component which can fulfill one of three functions that simplify this problem:
- A Translator function is able to translate one search format into another and is understood by multiple 1EdTech and existing repositories.
- An Aggregator function that gathers 1EdTech and/or other meta-data from multiple repositories and makes this meta-data available for searching.
- A Federator function that passes a search query to multiple repositories and manages the responses.
3.1 Search/Expose
The Search reference model defines the searching of the meta-data associated with content exposed by repositories. The reference model is illustrated in Figure 3.2 below.
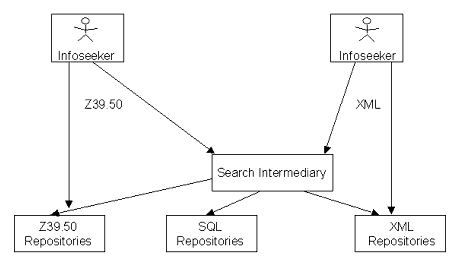
There are two dominant characteristics of the Search reference model. First, it supports a diverse range of configurations for conducting search. These will offer both broad technology-based and community-focused experiences for searching the digital content universe. Second, it provides an optional mediation layer to allow the querying of distributed, heterogeneous meta-data sources.
3.1.1 Recommendations for Query Language
- XQuery for searching 1EdTech (XML) meta-data format. XQuery is being developed by a W3C working group. It has a well-developed grammar, and several commercial implementations are emerging from the community. Its strengths are query-by-example and structured searches of XML documents and repositories containing 1EdTech meta-data. The most recent working drafts of the specification are dated November 2002.
- Z39.50 for searching library information. This search provides a grammar for searching Z39.50 repositories either directly or through an intermediate search engine.
There are three types of SOAP messaging with or without attachments:
- RPC (known arguments to well-known methods)
- Messaging (generic arguments to well-known methods)
- Session (generic arguments with context)
3.2 Gather/Expose
The Gather reference model defines the soliciting of meta-data exposed by repositories and the aggregation of the meta-data for use in subsequent searches, and the aggregations of the meta-data to create a new meta-data repository. The aggregated repository becomes another repository available for Search/Expose Alert/Expose functions. The reference model is represented in Figure 3.3 below.
The Gather component may interact with repositories in one of two ways. It either actively solicits meta-data (newly created, updated, or deleted) from a repository (pull), or subscribes to a meta-data notification service (newly created, updated, or deleted) provided by the repository or by an adapter external to a repository that enables messaging between the repository and other users (push).
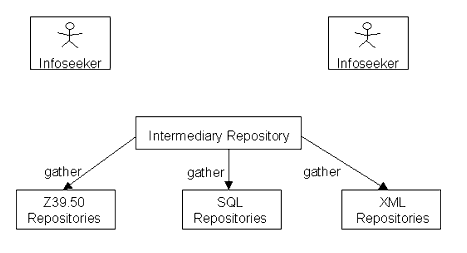
3.2.1 Recommendations for "Pull" Gather
The Open Archive Initiative (OAI) provides a simple model for Pull Gather. OAI meta-data aggregators perform a periodic search of target repositories and retrieve meta-data based on a range of dates. Date is the primary criterion used in this model and it requires a meta-data element that contains the date on which the meta-data was added or updated. Qualification by sets is also possible. This has the advantage of being very simple and can be effective in providing completeness in harvesting meta-data.
It is expected that the OAI model will be sufficient for the 1EdTech repositories context. OAI mandates that repositories supply Dublin Core as a minimal lingua franca for OAI compliance, but repositories are free to support any additional XML meta-data format, such as MARC XML or ONIX.
To use the OAI model in the 1EdTech context, an element within the 1EdTech Meta-Data Specification will have to be defined to provide the date information required to allow the Gather Engine to determine which meta-data has been added or updated since the last time the spider harvested from that repository. Note that the Gather Engine is responsible for keeping the date information stating when it last harvested from a particular repository. There are issues with the OAI model working with meta-data structures that do not contain the required date element.
OAI currently uses XML messages over HTTP. OAI Protocol 1.1 Documentation is available at: http://www.openarchives.org/OAI/openarchivesprotocol.html
Another option for Pull Gather is to periodically gather all meta-data records from all target repositories. This ranks very high on completeness, but is an inefficient utilization of resources as potentially millions of records would repeatedly be pulled over the network.
3.2.2 Recommendations for "Push" Gather
Push Gather is a special, basic case of Alert. Whenever a new meta-data record is added or updated, repositories could send an alert to subscribing aggregators. This could be a simple message saying that new meta-data exists at this repository, or could be the complete meta-data, which could then be incorporated into the meta-data repository and would then be available for search.
The mechanism for Push Gather could also be provided by an adapter external to a particular repository. This adapter could forward meta-data to the intermediate aggregators simultaneously as new content is added to the repository. This adapter could also manage message translation between the network and the repository's native capabilities.
3.3 Alert/Expose
The DRI Project Group regards the Alert function as a possible component of a digital repository or an intermediary aggregator service and envisions that e-mail/SMTP (Simple Mail Transfer Protocol) could provide this functionality. However, the Alert function is regarded as out of scope for Phase 1 of the DRI specification. For more detail about how the Alert function might work, see the Appendix in the DRI Best Practice Guide.
3.4 Submit/Store
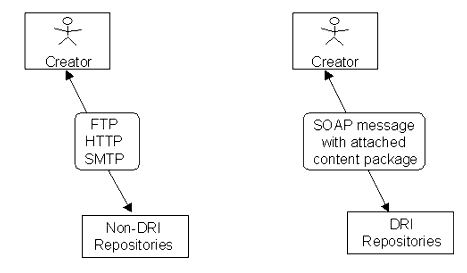
Submit/Store functionality refers to the way an object is moved to a repository from a given network-accessible location, and how the object will then be represented in that repository for access. The location from which an object is moved can be another repository, a learning management system, a developer's hard-drive, or any other networked location. It is anticipated that existing repository systems may already have established means for achieving Submit/Store functions (typically FTP). This specification provides no particular recommendations for legacy repository systems, but wishes to draw attention to the following weaknesses of FTP as a transport mechanism for learning objects or other assets:
- Plain FTP provides no encryption capabilities, making it unsuitable for the transport of copyright controlled assets.
- Providing FTP server access to a networked location presents widely-recognized security risks.
- FTP does not provide means of confirming the successful delivery of assets from one networked location to another.
In the case of more recently developed repositories that deal specifically with learning objects, this specification makes significant reference to the 1EdTech Content Packaging Specification. The Content Packaging Specification defines "interoperability between systems that wish to import, export, aggregate, and disaggregate packages of content." A Content Package comprises a compressed file package (preferably a zip file) that contains the learning object, its meta-data record, and a manifest describing the contents of the package.
3.4.1 Submit
In the case of a learning object repository that is compliant with the DRI specification, the Submit function shall be satisfied through the transmission of an 1EdTech-compliant Content Package using SOAP Messages with attachments. SOAP with attachments refers to a W3C specification that "defines a binding for a SOAP 1.1 message" in such a way that the "MIME multipart mechanism for encapsulation of compound documents can be used to bundle entities related to the SOAP 1.1 message such as attachments." In the case of the Submit function, these attachments shall take the form of one or more 1EdTech-compliant Content Packages.
3.4.2 Store
The Store function is understood simply as the ability of the repository to present an 1EdTech Content Package at some level of its operation.
Figure 3.5 indicates how the Submit/Store functionality would accommodate both digital repositories that use or do not use the 1EdTech DRI recommendations.
3.5 Request/Deliver
The Request functional component allows a resource utilizer that has located a meta-data record via the Search (and possibly via the Alert) function to request access to the learning object or other resource described by the meta-data. Deliver refers to the response from the repository which provides access to the resource.
3.5.1 Exclusions from Scope
In a hybrid environment, the resources discovered via a cross-domain search potentially include resources that are not learning objects and/or are not available online. Version 1.0 of the DRI Specification deals only with the case of requesting and delivering online resources from object repositories.
Digital Rights Management, including verification that the resource utilizer is authorized to access a resource, and resolution of an object identifier to locate the most appropriate copy are not covered here. These functions are carried out within the functional model by the Access Management Service. Recommendations on location services and technologies, including DOIs and OpenURLs, are included in the DRI Best Practice Guide.
Verification of the delivery of materials is not covered in this version of the specification. E-commerce and payment processing is handled by another functional component.
3.5.2 Request/Deliver Mechanism
The starting point for the Request/Deliver function is a pointer to a location of a resource. If the meta-data record has been located via the Search function on 1EdTech-compliant meta-data, then this pointer will be contained in element 4.3 <location> of the meta-data record. If the resource utilizer is not authorized to access the resource, then the access management services should prevent access to the resource. Implementation of Access Management / Rights Management services are outside the scope of specification. Implementation mechanisms may include blocking the presentation of the <location> data element to the user or refusing access to the resource on receipt of the Request.
The meta-data element may consist of a list of locations or a method which resolves to a location or list of locations. The latter may be a DOI or an OpenURL. The resolver functional component is responsible for returning the list of locations. The location returned should resolve to a URL. Linking to this URL shall initiate the Request. The protocol used to Deliver the learning object will vary depending on the format of the object but will include:
http: for online materials including html, java, and pdf
http: for streaming access to materials (audio, video, etc.)
ftp: for access to documents, executables, etc.
4. General Messaging Model
The Messaging model is used to provide general communication between the components defined by the DRI Information Model. The basic messaging model is stateless, consisting of a single request message from source to destination followed by a single response message from destination to source. Additional messaging models may be supported in the future.
The basic message has two parts: a message header and a message body.
message header body
Message Header
The message header contains addressing and minimal security information.
No provision for routing, alternate returns addresses, time-to-live, messaging sequencing, and so on is made in the initial model. These are all anticipated in subsequent versions.
Message-level authentication is provided by an extensible 'security' element.
header message type destination address message authentication
The destination address is specified as a URI.
Message Body
The message body consists of zero or more payloads, with zero or more 'audit' elements.
body payload(s) audit element(s)
Arbitrary payloads may be used, as long as they meet the requirements of the relevant message and transport bindings.
'Audit' elements allow the addition of relevant audit information to any message. This could include information relating to payment, usage, performance, and so on. 'Audit' elements typically accumulate as a message moves through the system. In particular, when a response is returned, it includes all the 'audit' elements from the corresponding request.
Message Security
Excepting the message-level authentication identified in the message header element described above, no explicit security mechanism is identified in the current model. Some level of message-level security may be provided externally to the basic message itself. For instance, HTTPS may be used to provide message encryption when HTTP is used as a transport binding (see the Messaging section in the DRI XML Binding).
4.1 Open Issues
This section records issues that have been identified but not addressed. The appropriate standards communities should address many of these, as they represent common problems.
Message Security
Message integrity and non-repudiation
Message-level encryption
Cascaded Messages
A model that supports cascaded messages is needed to handle alerts, transactions, hooks to other systems, and so on.
Failures
Where possible, failure messages are handled at the application level, generally as a return message. Within the SOAP/HTTP binding, 'out-of-band' failures will use the SOAP failure message mechanism.
Canceling a Query
The SOAP/HTTP message binding does not provide a way to directly cancel a message once issued, in particular, cancellation of a currently executing (distributed) query.
Incomplete Query
In the case when a query doesn't complete for some reason, the use of a time-out mechanism at both ends of the message is recommended.
5. High Level Overview of Use Cases for a Learning Repository
The following DRI use cases describe scenarios where certain actors assume specific roles within a learning repository. Before exploring the use cases, carefully read the section below on actors to better understand the roles that these actors assume.
5.1 Actors
Each actor in the use cases described below will be acting in one of the following roles described earlier: Creator, Learner, Infoseeker, or Software Agent.
1. Creator Roles 1.1 Single Repository Use Cases
Actor 1: Training course creator in a corporate setting (perhaps a defense contractor or pharmaceutical company) who is using a single repository to develop courses or reference materials related to a particular product for use in either in-house training materials or for training materials for customers.
1.2 Multiple Repositories Use Cases
Actor 2: Someone working in a publishing company context where there are several different subsidiary publishing arms and the person is trying to pull materials from the different subsidiaries' repositories to develop new cross-disciplinary materials to sell.
2. Learner Roles 2.1 Single Repository Use Cases
Actor 3: Employee or customer in a corporate setting who is using the single repository to find a training course or reference materials needed to raise the individual's competency with respect to a particular product.
Actor 4: Training coordinator in a corporate setting who associates competencies with the courses or learning objects in a repository.
2.2 Multiple Repositories Use Cases
Actor 5: Someone who has purchased the cross-disciplinary training material created by Actor 2 and would like to receive periodic updates to the training material whenever the publishing company changes the material.
3. Infoseeker Roles 3.1 Single Repository Use Cases
Actor 6: Employee who is searching via a portal for information related to a particular subject.
3.2 Multiple Repositories Use Cases
Actor 7: Someone who is searching for information related to a subject that may be contained in multiple repositories.
4. Software Agent Roles Actor 8: LMS software application
Actor 9: LCMS software application
Actor 10: Portal software application
Actor 11: Aggregator Repository
5.2 Use Cases
5.2.1 Create and Modify Resources
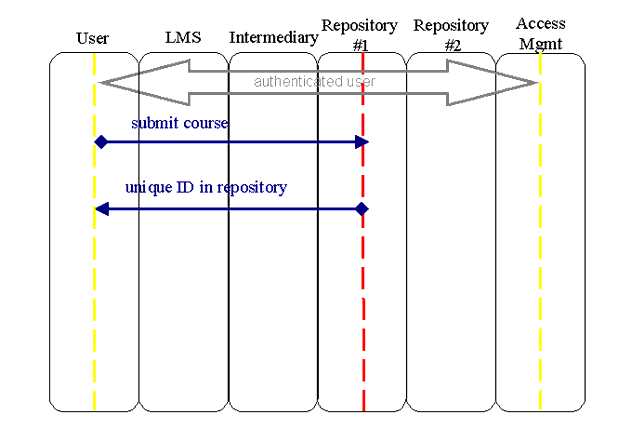
to the repository.
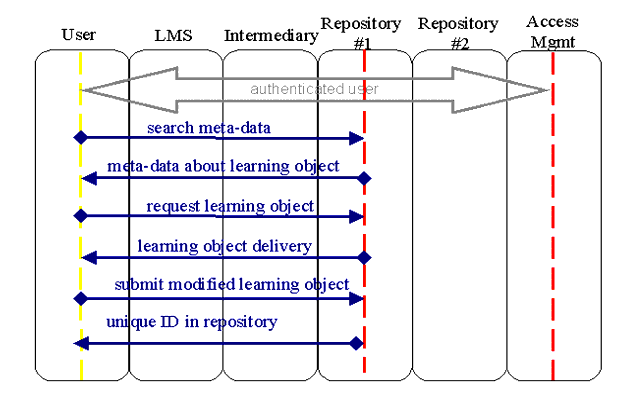
5.2.2 Discover Resources
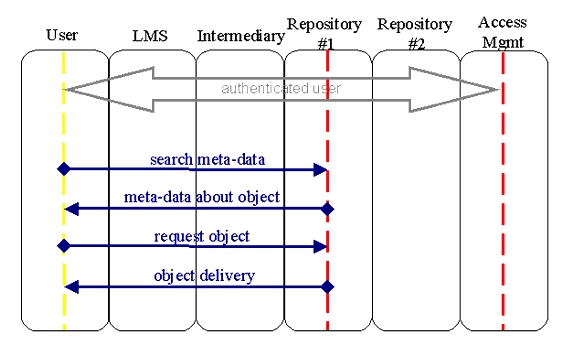

requests a discovered resource.
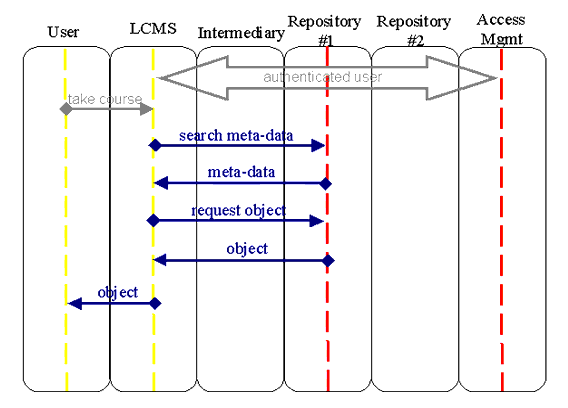
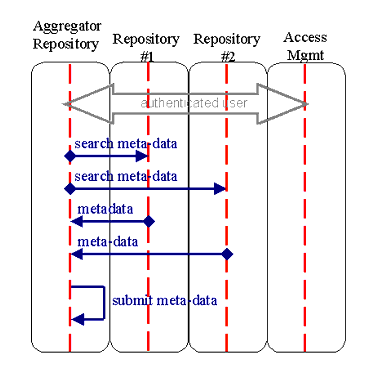
populates its own repository.
5.2.3 Notification of Modification of Resources
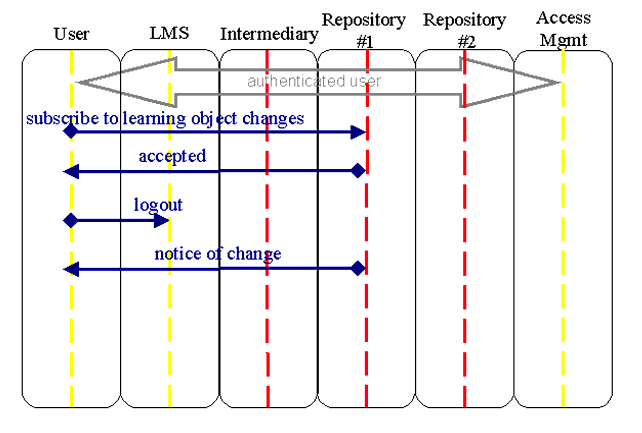
to the meta-data in a repository.
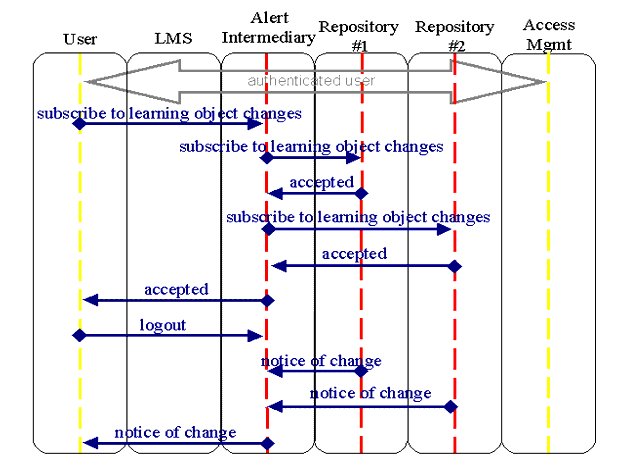
to the meta-data in multiple repositories.
About This Document
| Title | 1EdTech Digital Repositories Interoperability - Core Functions Information Model |
| Editors | Kevin Riley (1EdTech), Mark McKell (1EdTech) |
| Team Co-Lead | Jon Mason (1EdTech Australia - DEST) |
| Version | 1.0 |
| Version Date | 13 January 2003 |
| Status | Final Specification |
| Summary | This document describes the Information Model for the 1EdTech Digital Repositories Interoperability Specification. |
| Revision Information | 13 January 2003 |
| Document Location | http://www.imsglobal.org/digitalrepositories/driv1p0/imsdri_infov1p0.html |
List of Contributors
The following individuals contributed to the development of this specification:
Revision History
Index
A
agent 1, 2, 3
aggregator 1, 2, 3
Architecture 1
architecture 1, 2
asset 1, 2
C
Content Packaging 1, 2
core functions 1, 2
creator 1, 2, 3
L
LCMS 1, 2
learner 1, 2, 3
LMS 1, 2
M
Meta-data
Version 1
meta-data 1, 2, 3, 4, 5, 6
S
Scope 1
scope 1, 2, 3
SMTP 1
SOAP 1, 2, 3, 4, 5, 6
1EdTech Consortium, Inc. ("1EdTech") is publishing the information contained in this 1EdTech Digital Repositories Interoperability - Core Functions Information Model ("Specification") for purposes of scientific, experimental, and scholarly collaboration only.
1EdTech makes no warranty or representation regarding the accuracy or completeness of the Specification.
This material is provided on an "As Is" and "As Available" basis.
The Specification is at all times subject to change and revision without notice.
It is your sole responsibility to evaluate the usefulness, accuracy, and completeness of the Specification as it relates to you.
1EdTech would appreciate receiving your comments and suggestions.
Please contact 1EdTech through our website at http://www.imsglobal.org
Please refer to Document Name: 1EdTech Digital Repositories Interoperability - Core Functions Information Model Revision: 13 January 2003
