 |
1EdTech Learning Resource Meta-Data Best Practice and Implementation Guide Version 1.2.1 Final Specification |
| Copyright © 2001 1EdTech Consortium, Inc. All Rights Reserved. The 1EdTech Logo is a trademark of 1EdTech Consortium, Inc. Document Name: 1EdTech Learning Resource Meta-Data Best Practice and Implementation Guide Revision: 28 September 2001
|
IPR and Distribution Notices
Recipients of this document are requested to submit, with their comments, notification of any relevant patent claims or other intellectual property rights of which they may be aware that might be infringed by any implementation of the specification set forth in this document, and to provide supporting documentation.
1EdTech takes no position regarding the validity or scope of any intellectual property or other rights that might be claimed to pertain to the implementation or use of the technology described in this document or the extent to which any license under such rights might or might not be available; neither does it represent that it has made any effort to identify any such rights. Information on 1EdTech's procedures with respect to rights in 1EdTech specifications can be found at the 1EdTech Intellectual Property Rights web page: http://www.imsglobal.org/ipr/imsipr_policyFinal.pdf.
Copyright © 2001 1EdTech Consortium. All Rights Reserved.
Permission is granted to all parties to use excerpts from this document as needed in producing requests for proposals.
Use of this specification to develop products or services is governed by the license with 1EdTech found on the 1EdTech website: http://www.imsglobal.org/license.html.
The limited permissions granted above are perpetual and will not be revoked by 1EdTech or its successors or assigns.
THIS SPECIFICATION IS BEING OFFERED WITHOUT ANY WARRANTY WHATSOEVER, AND IN PARTICULAR, ANY WARRANTY OF NONINFRINGEMENT IS EXPRESSLY DISCLAIMED. ANY USE OF THIS SPECIFICATION SHALL BE MADE ENTIRELY AT THE IMPLEMENTER'S OWN RISK, AND NEITHER THE CONSORTIUM, NOR ANY OF ITS MEMBERS OR SUBMITTERS, SHALL HAVE ANY LIABILITY WHATSOEVER TO ANY IMPLEMENTER OR THIRD PARTY FOR ANY DAMAGES OF ANY NATURE WHATSOEVER, DIRECTLY OR INDIRECTLY, ARISING FROM THE USE OF THIS SPECIFICATION.
Table of Contents
1. Introduction
1.1 Background
1.2 Scope
2. Meta-Data system
2.1 Overview
2.2 IEEE Meta-Data Elements and Structure
2.3 Conformance
2.3.1 Meta-Data Instance Conformance
2.3.2 Meta-Data Application Conformance
2.4 Extensions
3. Taxonomy and Vocabulary Guide
3.1 Rationale
3.2 Targeted Elements
3.3 Results
3.4 Conclusions and Recommendations
4. 1EdTech Implementation Guide
4.1 Planning
4.1.1 Identify Appropriate Taxonomies and Vocabularies
4.1.2 Define Proprietary Extensions
4.2 Create a Meta-Data Instance
4.2.1 Preserve Meta-Data
4.3 Reading a Meta-Data Instance
4.3.1 Testing an Instance's Conformance
4.3.2 Exception Handling
5. Dublin Core Mapping
5.1 Introduction
5.2 Dublin Core Element Descriptions
Appendix A - Additional Resources
Appendix B - Possible Future Directions
B.1 Collapsing Elements into Attributes
B.2 Creating 1EdTech Vocabulary
Appendix C - List of Contributors
About This Document
Revision History
Index
1. Introduction
Designers and developers of online learning materials have an enormous variety of software tools at their disposal for creating learning resources. These tools range from simple presentation software packages to more complex authoring environments. They can be very useful in allowing developers the opportunity to create learning resources that might otherwise require extensive programming skills. Unfortunately, the wide variety of software tools available from a wide variety of vendors produce instructional materials that do not share a common mechanism for finding and using these resources.
Descriptive labels can be used to index learning resources to make them easier to find and use. Such labels are "data about data" and are referred to as "meta-data". An example of meta-data is the label on a can of soup, which describes the can's ingredients, weight, cost, and so forth. Another example is a card in a library's card catalog, which describes a book, its author, subject, location within the library, and so forth.
A meta-data specification makes the process of finding and using a resource more efficient by providing a structure of defined elements that describe, or catalog the learning resource, along with requirements about how the elements are to be used and represented.
1.1 Background
In 1997, the 1EdTech Project, part of the non-profit EDUCOM consortium (now EDUCAUSE) of US institutions of higher education and their vendor partners, established an effort to develop open, market-based standards for online learning, including specifications for learning content meta-data.
Also in 1997, groups within the National Institute for Standards and Technology (NIST) and the IEEE P.1484 study group (now the IEEE Learning Technology Standards Committee - LTSC) began similar efforts. The NIST effort merged with the 1EdTech effort, and 1EdTech began collaborating with the ARIADNE Project, a European Project with an active meta-data definition effort.
In 1998, 1EdTech and ARIADNE submitted a joint proposal and specification to IEEE, which formed the basis for the IEEE Learning Object Meta-Data (LOM) Draft Standard, which was a classification for a pre-draft IEEE Draft Standard. 1EdTech publicized the IEEE work through the 1EdTech community in the US, UK, Europe, Australia, and Singapore during 1999 and brought the resulting feedback into the ongoing specification development process.
1.2 Scope
The IEEE LOM Draft Standard defines a set of meta-data elements that can be used to describe learning resources. This includes the element names, definitions, datatypes, and field lengths. The specification also defines a conceptual structure for the meta-data. The specification includes conformance statements for how meta-data documents must be organized and how applications must behave in order to be considered IEEE-conforming.
The IEEE LOM Draft Standard is intended to support consistent definition of meta-data elements across multiple implementations, but does not (at the time of this writing) include information on how to represent meta-data in a machine-readable format, necessary for exchanging meta-data. The 1EdTech developed a representation of the meta-data in XML (eXensible Markup Language).
The 1EdTech Learning Resource Meta-Data Best Practice and Implementation Guide therefore includes or references:
- IEEE Learning Object Meta-Data Working Draft, Version 6.1
- 1EdTech Learning Resource Meta-Data XML Binding, Version 1.2
- 1EdTech Learning Resource Meta-Data Information Model, Version 1.2
- 1EdTech Taxonomy and Vocabulary Lists
The 1EdTech Learning Resource Meta-Data Best Practice and Implementation Guide provides general guidance about how an application may use LOM meta-data elements. The 1EdTech Learning Resource XML Binding specification provides a sample XML representation and XML control files (DTD, XSD) to assist developers with their meta-data implementations. None of these IEEE or 1EdTech documents address details of meta-data implementation, such as its architecture, programming language, and data storage approach.
A previous instance of this document described a "short list" of LOM meta-data elements called the 1EdTech Core that was hoped to simplify meta-data implementation. This expectation has not been met. Therefore, the 1EdTech drops any distinction of a "Core" or "Standard Extension Library" set of LOM elements.
The 1EdTech will continue to offer guidance and support documents related to the IEEE meta-data efforts. Most often, these documents will focus on implementation and binding issues. The 1EdTech community will continue to present the IEEE community with reference binding and implementation documents for a variety of learning resource needs such as enterprise interoperability, content packaging, and learning management. It is hoped that such reference documents may be helpful in the development of IEEE sanctioned binding and implementation guidelines.
2. Meta-Data system
2.1 Overview
The IEEE conceptual model for meta-data definitions is a hierarchy. At the top of the hierarchy is the "root" element. The root element contains many sub-elements. If a sub-element itself contains additional sub-elements it is called a "branch." Sub-elements that do not contain any sub-elements are called "leaves." This entire hierarchical model is called the "tree structure" of a document. The relationship between the root, branches, and leaves is depicted in Figure 2.1 using sample elements from the IEEE LOM Draft Standard.
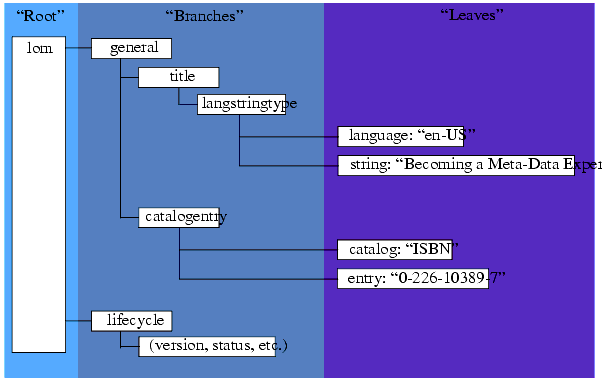
Each element in the meta-data hierarchy has a specific definition, datatype, and allowable value. All of the details about each individual meta-data element can be found in the 1EdTech Information Model document that is available at: http://www.imsglobal.org/metadata/imsmdv1p2p1/imsmd_infov1p2p1.html. The information model is based on the IEEE LTSC LOM Working Draft 6.1 available at http://ltsc.ieee.org/wg12/index.html.
2.2 IEEE Meta-Data Elements and Structure
The IEEE LOM Draft Standard lists all of the meta-data elements in a tabular format. Such a format enables easier reading of the element definitions, datatypes, notes, and examples as well as making it easier for printing. Sometimes it is useful to see a full representation of the meta-data as a hierarchy of elements. That representation is provided below in the form of successive graphics.
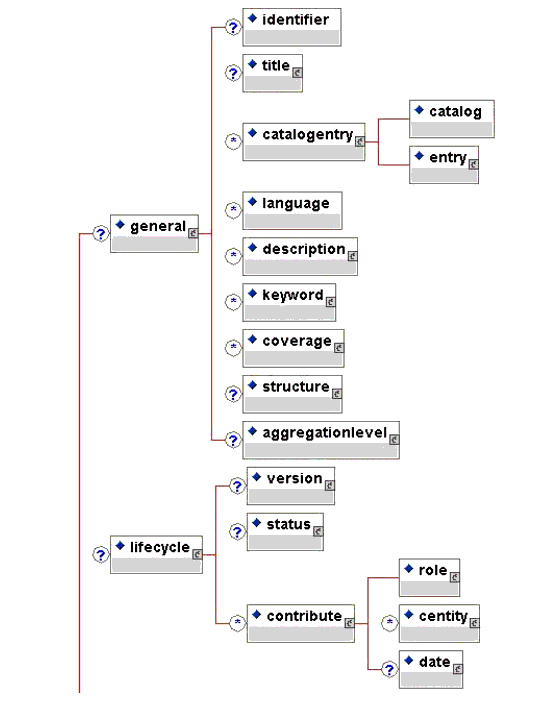
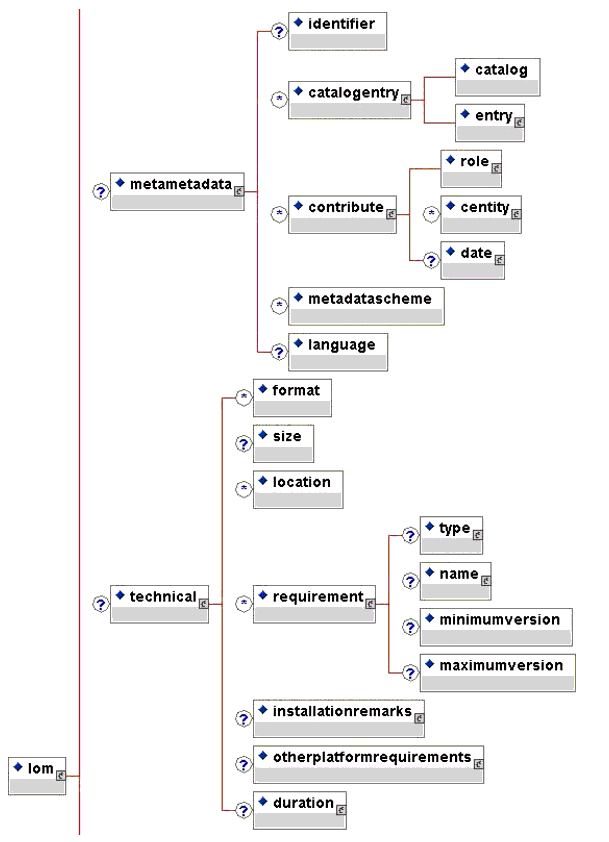
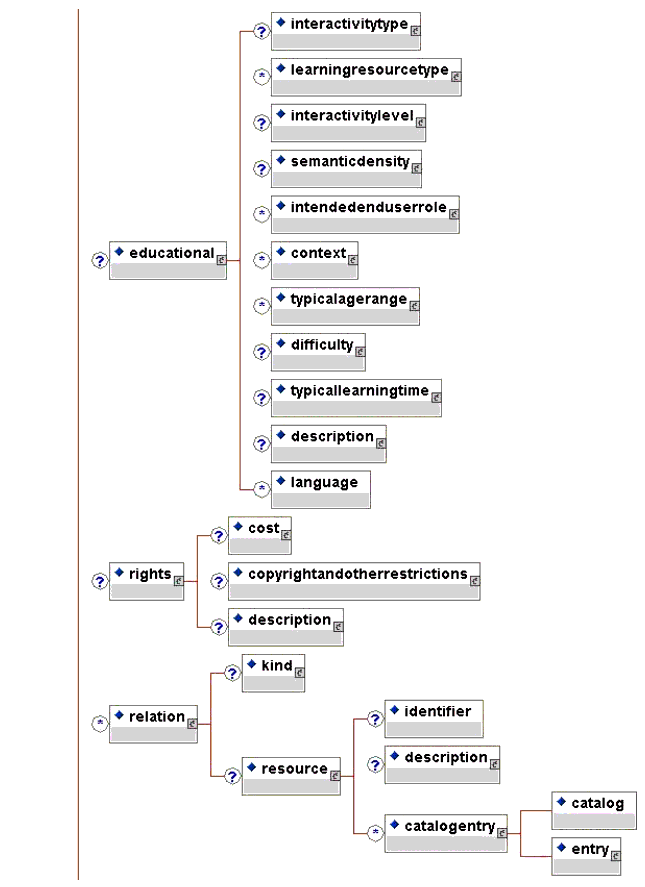
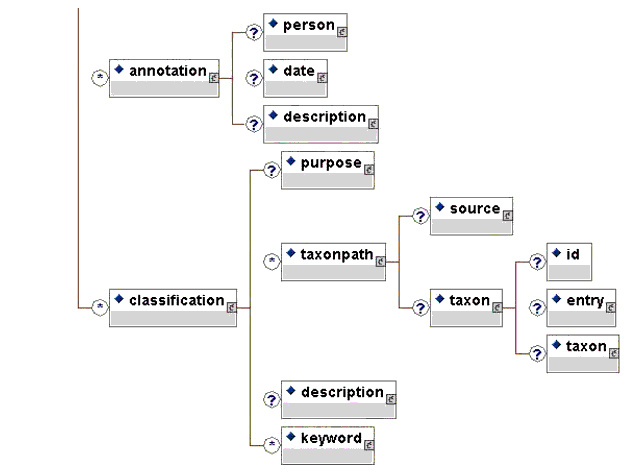
2.3 Conformance
"A conforming LOM metadata instance shall solely consist of LOM data elements." (Draft Standard for Learning Object Metadata, p. 8)
2.3.1 Meta-Data Instance Conformance
A meta-data instance conforms to the 1EdTech Meta-Data specification if it satisfies the following four requirements:
- The meta-data instance must contain one or more LOM element(s).
- All LOM elements in the meta-data instance are used to describe characteristics as defined by the LOM spec. (This means that one shall not abuse for instance, the <title> element to describe the fonts used in the document.)
- Values for LOM elements in the meta-data instance are structured as defined by the LOM specification and this structural information is carried within the instance. This means that the grouping in categories and subelements must be maintained. But it does not mean that representations cannot define mappings of this structure as they see fit. More specifically, an XML representation can use the xml:lang attribute to represent the <language> element of a langstringType value.
or
Bindings must carry equivalent information about the meta-data so that conversions between bindings do not induce loss of information as defined within the specification.
If the instance contains extensions to the LOM structure, then extension elements do not replace elements in the LOM structure.
2.3.2 Meta-Data Application Conformance
A meta-data application conforms to the 1EdTech Meta-Data specification if it satisfies the following two requirements:
- A conforming application must be able to process all LOM elements.
- If an application receives a conforming LOM meta-data instance, stores it, and then transmits it, then the application preserves the original meta-data instance during retransmission. The application is not required to preserve elements beyond the smallest permitted maximum number of items in a list or the characters beyond the smallest permitted maximum length of a string.
Caveat: Preservation means that the original instance is not changed in any way (i.e. that it "doesn't change a comma").
2.4 Extensions
There has been, and continues to be, much debate on extending meta-data for uses beyond search engine retrieval. At this point, individual developers and implementers must make decisions on how to best extend meta-data. See the 1EdTech Meta-Data Information Model and Binding documents for more information. 1EdTech recommends using XML Schema Definition language and its namespacing capability when using extensions. To accumulate knowledge of practice, 1EdTech also recommends that implementers and developers report their uses of extensions so that specific definitions and best practice can be incorporated into future versions of the specification.
The LOM rule regarding extensions is that they shall not conflict with or alter specified meta-data elements. The intent is to discourage developers from creating new elements that replace or duplicate elements in the LOM standard. For example, a meta-data instance should not have a new element, say TitleAndVersion, that is used as a replacement for already existing elements; in this case the title and version of the meta-data structure.
3. Taxonomy and Vocabulary Guide
Taxonomies and vocabularies are structured collections of terms that can serve as values for the meta-data elements discussed previously. They are part of the IEEE/1EdTech set of meta-data and are subject to best-practice policies. This subsection outlines current 1EdTech best-practice guidelines for taxonomies and vocabularies.
3.1 Rationale
Just as meta-data elements must accurately describe resources, the taxonomies and vocabularies that are their values also need to be precise. Just as meta-data elements must be easy to identify and use, taxonomies must be familiar both to developers and consumers of learning resources. Useful and usable meta-data elements and taxonomies together provide the foundation for a vigorous market in learning resources. Hence, best-practice considerations apply to taxonomies and vocabularies as forcefully as to other aspects of 1EdTech meta-data.
Viewed from this perspective, the goal of 1EdTech meta-data best practices as applied to taxonomies and vocabularies is to work with various communities interested in learning resources -- including developers, catalogers and consumers -- to foster the adoption of taxonomy standards that are shared as widely as possible. 1EdTech wants to make the communities aware of standardized (or at least popular and useful) taxonomies that might suit their needs; and to try to minimize the creation of new "home-grown" taxonomies by communities, when existing ones are perfectly adequate for their purposes.
Best practices guidelines concerning taxonomies and vocabularies do not require or even recommend a single taxonomy. As we learned from our earlier 1EdTech taxonomies work, no single controlled vocabulary such as, say, the Library of Congress Subject Headings (whose elements might be values for the discipline characteristic of classification.purpose) will be acceptable to all communities. Rather, the guidelines are based on a broad survey of various fields of use and of several 1EdTech meta-data properties or elements that take taxonomies as values. The guidelines will provide information about the many vocabularies that are "best" -- or at least commonly used -- to describe learning resources in these communities and for these meta-data properties.
3.2 Targeted Elements
The initial set of elements (the ones above the double line in the following table) was selected simply by looking at all properties in the IEEE LOM Draft Standard that take vocabularies or taxonomies as values. The criteria used to select important elements included whether the element was well-defined, understood by communities of users and also had emerging standard taxonomies associated with them (the "low hanging fruit" was generally viewed as more important)
This initial list of elements was extended through discussions with key contacts in the different fields of use. In particular, several of these groups were already developing and using vocabularies for additional 1EdTech meta-data properties (often ones that on our estimate appeared formative or even ill-defined). These have been included in cases where the controlled vocabularies appear to be relatively broadly used within a significant community or practice. and even though, in some cases, the vocabularies may not yet be stable. This means that some of the included vocabularies and taxonomies were ones that were popular in one field of use, but not necessarily in others; further, some whole elements or properties seem to be important in one field, but are rarely used in others, if at all.
2 In some cases the elements listed here are not ones that have values; rather values are associated with subelements. For example, values are associated with educational.typicallearningtime.datetime, not, strictly speaking, with educational.typicallearningtime. For simplicity, we use the ellipsis where it creates no ambiguity.
3 In most, but not all cases, these descriptions are taken from the 1EdTech Meta-Data specification.
3.3 Results
Discussions with key contacts in the various fields of use have enabled us to find several dozen vocabularies and taxonomies for targeted meta-data. The vocabularies differ across many dimensions. They range from small vocabulary lists, such as two options for metametadata.contribute.role (Creator, Validator), to multi-level discipline taxonomies comprising hundreds of terms. In many cases, such as classification.purpose [discipline], vocabularies are long-established; in others they are of relatively recent (home-grown) origin, and often used only by that field, or perhaps even a small community within a sector. For some elements (discipline again is an example), there are several competing taxonomies, even within a single field of use. For other elements, no dominant vocabulary has emerged for any field. The following paragraphs present our survey results in some detail, and summarize some best-practice guidelines.
3.4 Conclusions and Recommendations
The following table summarizes the results of our survey of taxonomies and vocabularies, listing formal and informal designations for schemes that were nominated for the elements discussed above by various fields of use. The table also points to sources (URLs for locations that list the vocabularies in complete detail, and in some cases that represent a controlling authority which maintains this information). Finally, the table also notes some summary characteristics for each taxonomy or vocabulary, limited mainly to comments on overall structure, origins, relationships to other vocabularies, stability and maturity, and whether the vocabulary is open or controlled.
For a couple of reasons not all of these vocabularies can be viewed as "best practices" in any strict sense, nor even highly recommended choices for their associated meta-data element. First, in some cases, such as discipline, several very mature alternative taxonomies are popular -- even within a single field of use. No single one emerges as best, except, perhaps, in very specialized fields, such as medicine. Second, many of the vocabularies are relatively unstable and immature. For these reasons, the taxonomies summarized below are, in general, best viewed as common practice guidelines, rather than best practice recommendations. In most cases, prospective users of taxonomies -- whether using them to describe known resources or to construct searches for unknown ones -- should consider their needs, the appropriate topic area and field, as well as the credibility of sources of alternative vocabularies, as part of the process of deciding what practice is best for them.
The table of common practice taxonomies also suggests features of several taxonomy services that could help users learn about available vocabulary alternatives and select ones appropriate to their meta-data needs. Perhaps the most important insight is that to choose the right vocabularies -- ones in particular that are shared by wide communities of practice -- users will need more than simple access to registries or repositories that catalog taxonomies and vocabularies. In addition, they will need access to information that can quickly educate them about the features of the various vocabulary alternatives available to them. The kinds of information that have surfaced during this survey and analysis include:
- element name
- field of use
- source location
- maintaining agency
- extensibility policies
- user community or audience
- stability
- completeness (and related quality judgements)
- relationships (with other taxonomies and vocabularies)
Pieces of information appearing first are just basic identification; others identify the source and communities of practice; the final ones are (sometimes subjective) assessments of the maturity of the vocabulary, relative to its user community. This list is not complete. A full- functional collection of taxonomy services built along these lines would not only allow users to choose the most appropriate vocabularies, but would also help extend the terms, as needed, in coordination with the maintaining authorities.
| Element | Taxonomy/ Vocabulary Scheme |
Fields of Use | Characteristics | Sources |
| general.language | RFC 1766 | US Higher Ed AU Higher Ed |
Stable and mature; national/international scope; controlled vocabulary | http://www.imc.org/rfc1766 |
| ABS 1267 | AU Higher Ed, AU K12 |
Relatively stable and mature; national scope; controlled vocabulary | ||
| ISO639; ISO3166 | AU Higher Ed, US Higher Ed |
Stable and mature; national/international scope; controlled vocabulary | http://www.iso.ch/ | |
| Z39.53 | US Higher Ed | Stable and mature; national/international scope; controlled vocabulary | http://www.oasis-open.org/cover/nisoLang3-1994.html | |
| classification.purpose [discipline] (also general.keywords, applied to subjects) |
LCC (Library of Congress Classification) | US Higher Ed | Stable and mature; national/international scope; controlled vocabulary | http://lcweb.loc.gov |
| |
|
|
|
|
| LCSH (Library of Congress Subject Headings) | US Higher Ed | Stable and mature; national/international scope; controlled vocabulary | http://lcweb.loc.gov | |
| DDC (Dewey Decimal Classification) | US Higher Ed | Stable and mature; national/international scope; controlled vocabulary | http://www.oclc.org/oclc/fp/ | |
| UDC (Universal Decimal Classification) | EU Higher Ed | Stable and mature; national/international scope; controlled vocabulary | http://zeus.slais.ucl.ac.uk/udc/ | |
| CIP (Classification of Instructional Programs) | US Higher Ed US Workforce Training |
Stable and mature; national scope; controlled vocabulary | http://nces.ed.gov/ | |
| DDC (top level with selective deepening) | US Higher Ed | Relatively unstable and immature; home-grown (variant of DDC with a terms from second- and third-levels added to first-level of DDC taxonomy) | http://merlot.org/home/SubjectCatIndex.po | |
| Doleta Subject Headings | US Workforce Training | Somewhat stable and mature; national scope; controlled vocabulary | http://www.fed-training.org/workspace/Flx-data/flx-provider.htm | |
| GEM subject taxonomy | US K12 | Relatively stable and mature; home-grown (began as DDC variant); controlled vocabulary | http://www.geminfo.org/Workbench/Metadata/Vocab_Subject.html | |
| SCIS Subject Headings | AU K12 | Stable and mature; national scope; controlled vocabulary | http://www.curriculum.edu.au/scis | |
| Singapore HE Subject taxonomy | Asia Higher Ed | New vocabulary, evolving; national scope; home-grown; controlled vocabulary | ?? | |
| Singapore K12 Subject taxonomy | Asia K12 Ed | New vocabulary, evolving; national scope; home-grown; controlled vocabulary | ?? | |
| general.aggregation level |
DoD cross-services harmonization | US Military Training | New and immature vocabulary; home-grown harmonization of vocabularies from different services | http://www.rhassociates.com/ADL-TWG/SCORM(0.7.3).doc |
| Singapore granularity list | Asia Higher Ed | New vocabulary, evolving; national scope; home-grown; controlled vocabulary | ?? | |
| technical.format | RFC 1521 | AU Higher Ed, US Military Training |
Relatively stable and mature; national/international scope; controlled vocabulary | http://www.isi.edu/in-notes/iana/assignments/media-types/media-types |
| GEM format controlled vocabulary | US K12 | Relatively stable and mature; home-grown (Subset of RFC 1521 media types); controlled vocabulary | http://www.geminfo.org/Workbench/Metadata/Vocab_Format.html | |
| Merlot format list | New vocabulary, mature; home-grown; restricted vocabulary | http://merlot.org/search/AdvArtifactSearch.po | ||
| educational.learningcontext (also classification.purpose [Educational Level] |
DoL default level | Uncertain stability and maturity; home-grown; restricted vocabulary | http://www.alx.org/alxoffer.html | |
| Edna.UserLevel | AU Higher Ed, AU K12 |
Somewhat stable and mature; home-grown; restricted vocabulary | http://www.edna.edu.au/EdNA/genericpage.html?file=/edna/aboutedna/metadata/schemes.html&sp=eec099eeeeeb#EDNA.Userlevel | |
| Singapore use level list | AU Higher Ed | New vocabulary, evolving; national scope; home-grown; controlled vocabulary | ||
| Gem grade controlled vocabulary | US K12, US Higher Ed |
Relatively stable and mature; home-grown; controlled vocabulary | http://www.geminfo.org/Workbench/Metadata/Vocab_Grade.html | |
| Merlot Primary Audience | US Higher Ed, US K12 Education |
New vocabulary, evolving; home-grown; restricted vocabulary | http://merlot.org/search/AdvArtifactSearch.po | |
| educational.learning resourcetype |
1EdTech default | US Military Training | New vocabulary, evolving; home-grown; open vocabulary | http://www.rhassociates.com/ADL-TWG/SCORM(0.7.3).doc |
| DC.Type "current thinking" | US Higher Ed | Relatively unstable and immature; home-grown; open vocabulary | http://www.agcrc.csiro.au/projects/3018CO/metadata/dc_tf/type_simple.html or http://purl.org/dc/documents/working_drafts/wd-typelist.htm |
|
| GEM resource-type controlled vocabulary | US K12 | Somewhat stable and mature; home-grown (Extension of DC recommended list); controlled vocabulary | http://www.geminfo.org/Workbench/Metadata/Vocab_Type.html | |
| Edna.Type | AU Higher Ed AU K12 |
Relatively unstable and immature; home-grown (based on DC.Type recommendation); controlled vocabulary | http://www.edna.edu.au/EdNA/genericpage.html?file=/edna/aboutedna/metadata/schemes.html&sp=eec099eeeeeb#EDNA.Type | |
| Singapore resource type list | Asia Higher Ed | New vocabulary, evolving; national scope; home-grown; controlled vocabulary | ?? | |
| Merlot form "Item Type" list | US Higher Ed | New vocabulary, evolving; home-grown; restricted vocabulary | http://merlot.org/search/AdvArtifactSearch.po | |
| educational. interactivitytype |
Singapore pedagogical approach list | Asia Higher Ed | New vocabulary, evolving; national scope; home-grown; controlled vocabulary | ?? |
| GEM pedagogy controlled vocabulary | US K12 | Somewhat stable and mature; home-grown; controlled vocabulary | http://www.geminfo.org/Workbench/Metadata/Vocab_Pedagogy.html | |
| educational. interactivitylevel |
Singapore interactivity list | Asia Higher Ed | New vocabulary, evolving; national scope; home-grown; controlled vocabulary | ?? |
| educational.intended enduserrole |
Singapore user role list | Asia Higher Ed | New vocabulary, evolving; national scope; home-grown; controlled vocabulary | ?? |
| GEM Audience controlled vocabulary | US Higher Ed | Somewhat stable and mature; home-grown; controlled vocabulary | http://www.geminfo.org/Workbench/Metadata/Vocab_Audience.html | |
| educational.difficulty | Singapore difficulty list | Asia Higher Ed | New vocabulary, evolving; national scope; home-grown; controlled vocabulary | ?? |
4. 1EdTech Implementation Guide
4.1 Planning
One of the first things you will need to do in planning your meta-data implementation is to identify all of the meta-data elements you believe your implementation will need to support. This can be done a couple of ways. One approach is to imagine how you will need to label the learning resources with which your implementation will deal. What kind of information should the resources carry with them? You might want to try this exercise without first looking through the 1EdTech meta-data structure or IEEE LOM Draft Standard.
Another approach is to imagine the information about learning resources that your implementation will need to work with and go through the 1EdTech meta-data list checking off each element that may serve your needs. You must keep your end users in mind as you begin listing meta-data elements. You should constantly ask yourself whether an element is really critical to your implementation or whether it is one that is just "nice to have". Meta-data elements are similar to features of a modern software application. Just as software engineers must be wary of "feature creep" so should learning resource implementers be wary of "meta-data creep". In a worst case scenario, your users could be expecting a convenient manner for easily identifying an online learning resource but instead, your application requires them to fill out enough fields to qualify them as an expert library resource cataloger.
4.1.1 Identify Appropriate Taxonomies and Vocabularies
It is often impossible to tell whether a meta-data element will meet your needs simply by its listed name and definition. There are quite a few elements within the 1EdTech meta-data whose true value lies in the taxonomy or vocabulary items that may serve as element values. An element such as LearningResourceType from the Educational category has at least six different taxonomies and vocabularies to choose from. You should select the taxonomy or vocabulary that best meets your needs from the common practice table above.
Taxonomies and vocabularies can be very useful in helping the meta-data creator avoid duplicative meta-data elements. For example, a meta-data creator may wish to indicate that the learning resource being created can be best classified as a "Prerequisite" type. If you do not carefully review the meta-data elements that have taxonomy and vocabulary listings, you may not notice that element number 9.1, called classification.purpose, has an associated, open vocabulary with the term "Prerequisite" in the listing. Those meta-data implementers who quickly add a proprietary extension when none is needed will thwart the efforts of others who expect to find resources labeled as "Prerequisite" by looking at element 9.1 for that information. The suggested practice is to always review the available taxonomies and vocabularies before creating new elements.
4.1.2 Define Proprietary Extensions
As you go through the exercise of identifying elements, you may discover information that simply cannot be adequately captured using any of the available 1EdTech meta-data elements. The IEEE LOM Draft Standard does allow for the extension of the meta-data instance with proprietary meta-data elements and structures. As mentioned above, the decision to implement new extensions to the 1EdTech meta-data should not be taken lightly, because extensions affect interoperability. Great care was taken by many people representing many different learning and training interests to make as comprehensive a meta-data specification as possible.
1EdTech defines the <extension> element for use when building extensions using a Document Type Definition (DTD) control file. The <extension> element is optional in the DTD only where it is declared. See the 1EdTech Meta-Data DTD: http://www.imsglobal.org/xml/imsmd_rootv1p2.dtd.
Using extensions with more than one DTD control file is problematic. 1EdTech recommends using XML Schema Definition (XSD) language and its namespacing capability when using extensions. For more infromation about namespacing, refer to the W3C Recommendation for Namespaces (http://www.w3.org/TR/1999/REC-xml-names-19990114). See the 1EdTech Meta-Data Schema Definition files: http://www.imsglobal.org/metadata.
The W3C Recommendation for Namespaces does not specify how namespaces are to be used. The introductory abstract states:
"XML namespaces provide a simple method for qualifying element and attribute names used in Extensible Markup Language documents by associating them with namespaces identified by URI references."
Namespaces provide a simple way of qualifying element and attribute names to create uniqueness and/or to indicate the source of the element or attribute, particularly if there are conflicts with other systems that have created the same element or attribute name. The manner in which namespaces may be interpreted by applications is not specified. There are two general approaches to namespaces:
- Use to point to a specific encoding schema for machine interpretation, and
- Use as a reference for uniqueness and possibly definition (semantics).
These two approaches are not mutually exclusive. A namespace is applied as a prefix to an element or attribute name:
<adl:subject>
The prefix of adl: is the qualifier, and must be defined elsewhere in the document. 1EdTech does not specify how namespaces are to be resolved (semantically or for machine interpretation).
4.2 Create a Meta-Data Instance
With your elements, taxonomies, and extensions chosen, it is time to create your meta-data instance. The 1EdTech community has chosen XML as the first language in which the 1EdTech meta-data will be represented. Creating an XML instance is quite straightforward and will seem very familiar to those developers who have spent a lot of time working with HTML. XML uses many of the tagging and formatting conventions found in HTML. 1EdTech recommends using tools for generating XML instances to reduce the number of common errors.
Your primary resource in creating proper meta-data instances is the 1EdTech Learning Resource Meta-Data XML Binding. This document used in tandem with the samples provided in the specification package help illustrate how to properly organize your own meta-data instnaces.
4.2.1 Preserve Meta-Data
If a meta-data application does not create meta-data instances, then it likely will have some capacity for retransmitting instances or preserving them. The idea from the IEEE suggested conformance wording is that if an application receives a conforming meta-data instance and then retransmits that instance, it must do so without altering the instance at all. That means not even a single comma is changed. If an application is going to receive an instance and then make changes to that instance, then what the application has done is to create a new meta-data instance. This is an important point that implementers must adhere to.
The IEEE specifies values for the number of list elements and the number of allowable characters for string data. These value constraints are called "smallest permitted maximum" because they represent the threshold value a conforming application is required to preserve. If a string such as General.Title has a threshold length of 1000 characters and a meta-data instance is received that exceeds that number by, say 40 characters, the minimum level of conformance forced upon an application is that it preserve 1000 of those characters (the "smallest permitted maximum"). That is not to say the application is not allowed to preserve more, it is just that a threshold was set on values so that implementers can expect their application to be conforming if they preserve the smallest permitted maximum values.
4.3 Reading a Meta-Data Instance
Almost every application making use of meta-data will need to at least be able to properly read a meta-data instance. Fortunately, there are quite a number of very good XML parsers on the market that can assist with this task. In reality, parsing an XML instance is a relatively easy task. The more difficult tasks are determining your data structures for handling the parsed elements and presenting a coherent, well-designed user interface to your end users.
4.3.1 Testing an Instance's Conformance
The IEEE has not yet issued its formal statements on meta-data instance conformance, but there are still some conformance issues with which you should be concerned. As you try out your meta-data instances with various parsers and other tools, here are some questions to keep in mind:
- Does the instance validate against the XSD found in the 1EdTech Learning Resource Meta-Data XML Binding? Or, have you created a DTD or XSD that includes the elements of the IEEE you are using, plus any proprietary extensions?
- Are any extensions conflicting with the semantics or structure specified by the IEEE?
- Is the instance well-formed? Is the markup used properly from a parser's point of view?
- Is the structure correct? Are elements found where you would expect to find them based upon the IEEE LOM Draft Standard?
- Are the values for elements at least at the smallest permitted maximum threshold value?
If your answer to any of the questions above is "no", then you should investigate further. Just because you may have found some unexpected elements or different structures doesn't mean the instance should be thrown out or considered as non-conforming. There are often good reasons for an instance to not validate against the provided DTD or XSD, or to exceed the smallest permitted maximum value. One must simply be careful to identify those reasons and account for them in implementations.
4.3.2 Exception Handling
1EdTech cannot offer specific advice on how systems should handle exceptions. This is a very general question and errors arise from many sources. Proprietary use of extensions is also non-conforming with the LOM. See the discussion in Section 2.4.
4.3.2.1 Malformed Instances
1EdTech recommends the use of tools for generating XML instances to reduce the number of common errors. The most typical example of a "malformed" meta-data instance, using XML as our sample binding, is an instance that does not pass the XML test of being well-formed. These problems are likely to be found by XML parsers. Almost every parser will signal an exception when it encounters a malformed XML document. The most common error is a missing open or closed tag somewhere in the file. These problems are usually flagged by a good parser.
An XML document must have an associated DTD or Schema Definition to be declared valid. It is important to note that a well-formed document is not necessarily valid. A valid XML document is valid when it conforms to a specific schema. The 1EdTech Meta-Data DTD and Schema Definition documents can be found at http://www.imsglobal.org/metadata.
4.3.2.2 Instances that Exceed Length Thresholds
The LOM standard specifies smallest permitted maxima. When receiving instances, applications should make provision for instances that exceed the smallest permitted maximum. When creating instances, remember that the receiving applications have no obligation beyond supporting the smallest permitted maximum.
5. Dublin Core Mapping
5.1 Introduction
The IEEE Learning Object Meta-Data (LOM) specification contains elements that can be mapped to the Dublin Core Meta-Data Element set. The Dublin Core element set can be found at http://purl.org/DC/about/element_set.htm. The Dublin Core Home Page is found at http://purl.org/dc/.
The current list of Dublin Core elements and their general definitions were finalized in December 1996. The elements and their names are not expected to change substantively, though the application of some of them is currently experimental and subject to varying interpretation from implementation to implementation.
Dublin Core elements have a descriptive name intended to convey a common semantic understanding of the element. To promote global interoperability, a number of the element descriptions may be associated with a controlled vocabulary for the respective element values. It is assumed that other controlled vocabularies will be developed for interoperability within certain local domains. In the element descriptions below, a formal single-word label (expressed in all upper case) is specified to make the syntactic specification of elements simpler for encoding schemes. Each element is optional and repeatable.
It is important to note that just because it is possible to map Dublin Core and IEEE LOM elements to each other, this does not mean the elements are semantically or structurally equivalent. The reader should carefully study and understand both the meaning and intended usage of each element before utilizing it in a meta-data instance.
5.2 Dublin Core Element Descriptions
| Dublin Core # | Dublin Core Name | Dublin Core Label | IEEE Learning Object Meta-Data |
| 1 | Title | TITLE | general.title |
| |
The name given to the resource by the CREATOR or PUBLISHER. | ||
| 2 | Author or Creator | CREATOR | lifecycle.contribute when lifecycle.contribute.role has a value of "Author". |
| |
The person or organization primarily responsible for creating the intellectual content of the resource. For example, authors in the case of written documents, artists, photographers, or illustrators in the case of visual resources. | ||
| 3 | Subject and Keywords | SUBJECT | general.keywords. For those wishing more specificity of Subject, a category of classification can be used with a purpose of "Subject". classification has elements for description, keywords, and taxonpath(s) that are specific for the purpose. |
| |
The topic of the resource. Typically, subject will be expressed as keywords or phrases that describe the subject or content of the resource. The use of controlled vocabularies and formal classification schemas is encouraged. | ||
| 4 | Description | DESCRIPTION | general.Ddescription |
| |
A textual description of the content of the resource, including abstracts in the case of document-like objects or content descriptions in the case of visual resources. | ||
| 5 | Publisher | PUBLISHER | lifecycle.contribute when lifecycle.contribute.role has a value of "Publisher". |
| |
The entity responsible for making the resource available in its present form, such as a publishing house, a university department, or a corporate entity. | ||
| 6 | Other Contributor | CONTRIBUTOR | lifecycle.contribute with the type of contribution specified in lifecycle.contribute.role. lifecycle.contribute can be repeated. |
| |
A person or organization not specified in a CREATOR element who has made significant intellectual contributions to the resource but whose contribution is secondary to any person or organization specified in a CREATOR element (for example, editor, transcriber, and illustrator). | ||
| 7 | Date | DATE | lifecycle.contribute.date when lifecycle.contribute.role has a value of "Publisher". |
| |
The date the resource was made available in its present form. Recommended best practice is an 8 digit number in the form YYYY-MM-DD as defined in http://www.w3.org/TR/NOTE-datetime, a profile of ISO 8601. In this scheme, the date element 1994-11-05 corresponds to November 5, 1994. Many other schema are possible, but if used, they should be identified in an unambiguous manner. | ||
| 8 | Resource Type | TYPE | educational.learningresourcetype. |
| |
The category of the resource, such as home page, novel, poem, working paper, technical report, essay, dictionary. For the sake of interoperability, TYPE should be selected from an enumerated list that is under development in the workshop series at the time of publication of this document. See http://sunsite.berkeley.edu/Metadata/types.html for current thinking on the application of this element. | ||
| 9 | Format | FORMAT | technical.format |
| |
The data format of the resource, used to identify the software and possibly hardware that might be needed to display or operate the resource. For the sake of interoperability, FORMAT should be selected from an enumerated list that is under development in the workshop series at the time of publication of this document. | ||
| 10 | Resource Identifier | IDENTIFIER | general.catalogentry. greneral.identifier is currently a RESERVED term, as there is no specified method for creation of a GUID. |
| |
String or number used to uniquely identify the resource. Examples for networked resources include URLs and URNs (when implemented). Other globally-unique identifiers, such as International Standard Book Numbers (ISBN) or other formal names would also be candidates for this element in the case of off-line resources. | ||
| 11 | Source | SOURCE | relation.resource when the value of relation.kind is "IsBasedOn". This reduction is currently under consideration within the Dublin Core Community. |
| |
A string or number used to uniquely identify the work from which this resource was derived, if applicable. For example, a PDF version of a novel might have a SOURCE element containing an ISBN number for the physical book from which the PDF version was derived. | ||
| 12 | Language | LANGUAGE | general.language |
| |
Language(s) of the intellectual content of the resource. Where practical, the content of this field should coincide with RFC 1766. See: http://ds.internic.net/rfc/rfc1766.txt. | ||
| 13 | Relation | RELATION | relation.kind, relation.resource |
| |
The relationship of this resource to other resources. The intent of this element is to provide a means to express relationships among resources that have formal relationships to others, but exist as discrete resources themselves. For example, images in a document, chapters in a book, or items in a collection. Formal specification of RELATION is currently under development. Users and developers should understand that use of this element is currently considered to be experimental. | ||
| 14 | Coverage | COVERAGE | general.coverage |
| |
The spatial and/or temporal characteristics of the resource. Formal specification of COVERAGE is currently under development. Users and developers should understand that use of this element is currently considered to be experimental. | ||
| 15 | Rights Management | RIGHTS | rights.description |
| |
A link to a copyright notice, to a rights-management statement, or to a service that would provide information about terms of access to the resource. Formal specification of RIGHTS is currently under development. Users and developers should understand that use of this element is currently considered to be experimental. | ||
Appendix A - Additional Resources
IEEE Learning Object Meta-Data (LOM)
The IEEE Learning Object Meta-Data (LOM) Draft Standard can be found at: http://ltsc.ieee.org/doc/wg12/
1EdTech XML Documents
The imsmd_rootv1p2.dtd is located at: http://www.imsglobal.org/xml/imsmd_rootv1p2.dtd
The imsmd_rootv1p2p1.xsd is located at: http://www.imsglobal.org/xsd/imsmd_rootv1p2p1.xsd
1EdTech Meta-Data Documents
The 1EdTech Learning Resource Meta-Data XML Binding Specification v 1.1 can be found at: http://www.imsglobal.org/metadata/imsmdv1p2p1/imsmd_bindv1p2p1.html
The 1EdTech Learning Resource Meta-Data Information Model v1.1 document can be found at: http://www.imsglobal.org/metadata/imsmdv1p2p1/imsmd_infov1p2p1.html
Sample meta-data files and control documents in a ZIP file can be found at: http://www.imsglobal.org/metadata/
vCard Information
A variety of vCard related links can be found at: http://www.imc.org/pdi/
XML Resources
The XML specification and additional links can be found at: http://www.w3.org/XML/
Articles, software and many things related to XML can be found at: http://www.xml.com/
Information about Resource Description Framework (RDF) is located at: http://www.w3.org/RDF/
Information about the XML Namespaces recommendation can be found at: http://www.w3.org/TR/1999/REC-xml-names-19990114/
Appendix B - Possible Future Directions
This section describes various approaches and possible use cases that the 1EdTech Meta-Data Working Group may consider as recommendations for future version releases.
B.1 Collapsing Elements into Attributes
(added May 2001)
1EdTech may consider collapsing certain LOM elements into attributes. This has the potential for reducing parsing time and for allowing more advanced searching capabilities.
B.2 Creating 1EdTech Vocabulary
(added May 2001)
1EdTech may consider creating an 1EdTech wide vocabulary list for all elements that have a Vocabluary Type. If any members of the 1EdTech community have a set of vocabularies that they would like to submit to the Meta-Data Working Group for consideration, send it to the forum at: md-question@imsglobal.org.
Appendix C - List of Contributors
The following individuals contributed to the development of this specification:
About This Document
| Title | 1EdTech Learning Resource Meta-Data Best Practice and Implementation Guide |
| Editors | Schawn Thropp and Mark McKell |
| Version | 1.2.1 |
| Version Date | September 2001 |
| Status | Final Specification |
| Summary | This document provides updated information regarding 1EdTech Learning Resource Meta-Data Best Practice and Implementation Guide |
| Revision Information | 28 September 2001 |
| Purpose | Defines the Learning Resource Meta-Data Best Practice and Implementation Guide. |
| Document Location | http://www.imsglobal.org/metadata/imsmdv1p2p1/imsmd_bestv1p2p1.html |
Revision History
Index
A
ARIADNE 1
B
branch 1
C
Conformance 1, 2
Contributors 1
1EdTech Consortium, Inc. ("1EdTech") is publishing the information contained in this 1EdTech Learning Resource Meta-Data Best Practice and Implementation Guide ("Specification") for purposes of scientific, experimental, and scholarly collaboration only.
1EdTech makes no warranty or representation regarding the accuracy or completeness of the Specification.
This material is provided on an "As Is" and "As Available" basis.
The Specification is at all times subject to change and revision without notice.
It is your sole responsibility to evaluate the usefulness, accuracy, and completeness of the Specification as it relates to you.
1EdTech would appreciate receiving your comments and suggestions.
Please contact 1EdTech through our website at http://www.imsglobal.org
Please refer to Document Name: 1EdTech Learning Resource Meta-Data Best Practice and Implementation Guide Revision: 28 September 2001
