 |
1EdTech Vocabulary Definition Exchange Best Practice and Implementation Guide Version 1.0 Final Specification |
Copyright © 2004 1EdTech Consortium, Inc. All Rights Reserved.
The 1EdTech Logo is a trademark of 1EdTech Consortium, Inc.
Document Name: 1EdTech Vocabulary Definition Exchange Best Practice and Implementation Guide
Revision: 23 February 2004
IPR and Distribution Notices
Recipients of this document are requested to submit, with their comments, notification of any relevant patent claims or other intellectual property rights of which they may be aware that might be infringed by any implementation of the specification set forth in this document, and to provide supporting documentation.
1EdTech takes no position regarding the validity or scope of any intellectual property or other rights that might be claimed to pertain to the implementation or use of the technology described in this document or the extent to which any license under such rights might or might not be available; neither does it represent that it has made any effort to identify any such rights. Information on 1EdTech's procedures with respect to rights in 1EdTech specifications can be found at the 1EdTech Intellectual Property Rights web page: http://www.imsglobal.org/ipr/imsipr_policyFinal.pdf.
Copyright © 2004 1EdTech Consortium. All Rights Reserved.
Permission is granted to all parties to use excerpts from this document as needed in producing requests for proposals.
Use of this specification to develop products or services is governed by the license with 1EdTech found on the 1EdTech website: http://www.imsglobal.org/license.html.
The limited permissions granted above are perpetual and will not be revoked by 1EdTech or its successors or assigns.
THIS SPECIFICATION IS BEING OFFERED WITHOUT ANY WARRANTY WHATSOEVER, AND IN PARTICULAR, ANY WARRANTY OF NONINFRINGEMENT IS EXPRESSLY DISCLAIMED. ANY USE OF THIS SPECIFICATION SHALL BE MADE ENTIRELY AT THE IMPLEMENTER'S OWN RISK, AND NEITHER THE CONSORTIUM, NOR ANY OF ITS MEMBERS OR SUBMITTERS, SHALL HAVE ANY LIABILITY WHATSOEVER TO ANY IMPLEMENTER OR THIRD PARTY FOR ANY DAMAGES OF ANY NATURE WHATSOEVER, DIRECTLY OR INDIRECTLY, ARISING FROM THE USE OF THIS SPECIFICATION.
Table of Contents
1. Introduction
1.1 Overview and Relationship to Other Specifications
1.2 1EdTech Vocabulary Definition Exchange Specification Components
1.2.1 Information Model
1.2.2 XML Binding Guide
1.2.3 Best Practices and Implementation Guide (this document)
1.2.4 Conformance Requirements
2. Guidance on Use of Identifiers
2.1 General Guidance
2.1.1 Identifier Good Practice
2.2 Building Universally Unique Identifiers for Terms
2.3 Referencing VDEX-Defined Vocabulary Terms
3. Best Practices for Creating, Managing, and Using Vocabularies
4. Implementation Recommendations
4.1 XML Binding
4.2 Element-by-Element Recommendations
4.2.1 Vocabulary Identifier
4.2.2 Term Identifier
4.2.3 Caption
4.2.4 Media Descriptor
4.2.5 Relationship
4.2.6 Meta-data
4.2.7 Langstrings
4.3 Use of VDEX Instances with 1EdTech Content Packaging
4.4 Complex Vocabularies
4.4.1 Facetted Schemes
4.4.2 Micro-thesauri
4.4.3 Polyhierarchical Taxonomies
4.5 Extensibility and Related Issues
4.5.1 Extension of the VDEX Model
4.5.2 Use of the VDEX Model as a Component
4.6 Exchanging Fragments
4.7 Tracking Changes in Evolving Vocabularies
5. Examples
5.1 Instances of VDEX
5.1.1 The ISO Thesaurus Relations Expressed as a Flat List of Tokens
5.1.2 A Short Glossary of Eye-Related Terms
5.1.3 A Fragment of the MeSH Taxonomy
5.1.4 A Fragment of a Thesaurus Using the ISO Relationships and Referencing the
First Example
5.1.5 A Fragment of a Fictional Multilingual Thesaurus
5.1.6 A Fragment of a Multilingual Flat List of Tokens
5.1.7 An Fragment of the IEEE LOM Vocabulary
5.2 Other Examples
5.2.1 Using VDEX as a Content Type in an 1EdTech Content Package
5.2.2 Using Meta-Data with VDEX Instances
6. Application Scenarios
6.1 Automating Meta-Data Editor User Interfaces
6.1.1 Goal
6.1.2 Scenario
6.2 Meta-Data Creation Using an Application Profile
6.2.1 Goal
6.2.2 Scenario
6.2.3 Scenario Variant
6.3 Interpreting Meta-Data
6.3.1 Goal
6.3.2 Scenario
6.4 Supplying the Learner with a Glossary
6.4.1 Goal
6.4.2 Scenario
6.5 Locating an Appropriate Vocabulary
6.5.1 Goal
6.5.2 Scenario
6.6 Using a Thesaurus Service
6.6.1 Goal
6.6.2 Scenario
7. Master Reference Files for 1EdTech Specification Vocabularies
Appendix A - Additional Resources
About This Document
List of Contributors
Revision History
Index
1. Introduction
1.1 Overview and Relationship to Other Specifications
The 1EdTech Vocabulary Definition Exchange (VDEX) specification defines a grammar for the exchange of value lists of various classes: collections often denoted "vocabulary". Section 1.4.2 of the 1EdTech Vocabulary Definition Exchange Information Model provides some definitions of the classes of vocabulary that VDEX can be used for. The ISO prefers the terms "value domain" and "permitted value" for the data VDEX principally relates to (instead of the term "vocabulary"). Within 1EdTech and IEEE these have generally been called "vocabularies" and split into "source" and "value" pairs, although the vocabulary data types used in 1EdTech specifications and IEEE LOM are only one class of vocabulary that can be exchanged by VDEX.
VDEX considers two distinct categories of vocabulary, differentiated by the key used to identify a concept:
- vocabularies where the key is some sort of token and where this token effectively de-references a human language term (referred to as "tokenized terms" below)
- vocabularies where the key is a human language term (referred to as "human language terms" below).
The vocabulary data types used in IEEE LOM and most 1EdTech specifications are simple tokenized terms. Whereas some specifications provide a preferred list of permitted terms, i.e., a preferred value domain, it is common practice to permit alternative value domains to be defined by the users of 1EdTech specifications. VDEX aims to assist in the processes around the exchange and utilization of such domain-specific or community-specific value domains. It is worth noting that although the terms presented for value domains may be lexically identical to natural language terms, the terms are nevertheless formally tokens. The reader is recommended to inspect the IEEE LOM specification (see references) for examples.
An application profile for a specification, such as 1EdTech Meta-Data, would normally be agreed within a community or defined by a lead agency. This application profile would specify the value domains to be used for all elements of vocabulary data type. VDEX permits this to be achieved in a normative way. VDEX also permits additional information to be included with the definition of the value domain to allow the user of the terms to receive scope notes to help them apply the correct term. Because of the need to know the identity of the value domain in order to know the meaning of the permitted value, vocabulary data types are split into a declaration of the source of the vocabulary term (i.e., the domain) and the value of the term.
All 1EdTech specs and IEEE LOM 1484.12 standard that allow controlled terms/vocabularies to be expressed (especially as source+value pairs) are supported by the VDEX specification. VDEX makes it easier to unambiguously express application profiles and verify conformity and easier for tools to produce conforming meta-data because VDEX will allow publication of master reference data in a well-defined and consistent way.
Whereas vocabulary data types typically have an associated unstructured list of terms, IEEE LOM and 1EdTech Meta-Data both permit the expression of subject classifications from hierarchical vocabularies (taxonomies). Taxonomies often use structured identifiers that express the position of a term in the hierarchy. These identifiers are effectively language independent tokens that may be associated with any number of human language captions. VDEX permits the expression and exchange of taxonomic classification schemes, with scope notes if required, including information required to populate all of the "taxon path" branch of IEEE LOM or 1EdTech Meta-Data. The hierarchical structure of ordinary taxonomies is expressed as part of the VDEX Information Model.
Cataloging of resources in collections and indexing normally use lists of preferred terms but these are typically human language terms. A thesaurus is a common tool for this process and ISO 2788 defines, among other things, a set of standardized relationship types. VDEX enables thesauri to be expressed including these relationships but does not make them part of the Information Model. Instead, VDEX provides for terms to be related using arbitrary relationship types; in fact the relationship types are expressed as a vocabulary data type (as discussed above).
1.2 1EdTech Vocabulary Definition Exchange Specification Components
This document forms one of a set that comprise the 1EdTech Vocabulary Definition Exchange Specification version 1.0. Each document has a distinct scope:
1.2.1 Information Model
Describes the core aspects of the specification and contains parts that are normative for any binding claiming to use this Information Model. It contains details of: semantics, structure, data types, value spaces, multiplicity, and obligation (i.e., whether mandatory or optional).
1.2.2 XML Binding Guide
Describes a binding of the Information Model to XML version 1.0 and is normative for any XML instance that claims to use this binding, whether by reference to the specification or by declaration of the namespace reserved by the specification. In cases of error or omission, the Information Model takes precedence. The VDEX XML Binding is released with a control document using W3C XML Schema 1.0 that should be used in implementations.
1.2.3 Best Practices and Implementation Guide (this document)
Provides non-normative guidance on application of the Information Model and XML Binding. This includes reference to existing practice in handling information that this specification seeks to support and guidance on practices that will promote interoperability and durability. It also includes examples to illustrate how the conceptual framework maps to practical uses and to identify the relationship between this specification and related 1EdTech specifications. Implementers are encouraged, but not required, to follow guidance in this part of the specification.
1.2.4 Conformance Requirements
Provides a set of testable statements that may be used in relation to applications of the Information Model and XML Binding. These statements may form the basis of formal conformance testing and certification or informal assertions. This document makes no statement about the formal processes or method of certification or assertion; it only deals with criteria.
2. Guidance on Use of Identifiers
In most cases of application of VDEX, the choice and expression of identifiers for both the value domain (the vocabulary identifier) and the permitted values (the term identifiers) requires care. The core requirements of the Information Model are that:
- The vocabulary (i.e., value domain) identifier be universally unique and persistent;
- The term identifiers be locally unique within a vocabulary.
A term in the context of a value domain may be universally identified through a combination of the identity of the value domain (a universally unique part) and the identity of the term (a locally unique part).
2.1 General Guidance1
A number of current approaches exist for specific identification schemes that embody the core requirements of persistence and uniqueness. Some of the schemes have associated mechanisms to resolve the identifier to a resource. Appendix A - Additional Resources includes a sample of information sources on the topic. This section provides some general background.
The need for unique and persistent identifiers can be summed up as follows:
Unique and persistent identifiers are needed in order that, having discovered a resource, people can reliably cite it without having to perform the discovery again, and can pass the citation on for use by others. Similarly, software applications use identifiers to reliably reference resources, to share those references with other applications and to instantiate linkages between resources (for example, between a meta-data record and the resource it describes). Often, though not always, there is a related requirement that people and software can use the identifier as a mechanism for accessing the resource, i.e., that there is a service that 'resolves' the identifier to the current location of the resource.
2.1.1 Identifier Good Practice
In the context of VDEX data, identifiers should be:
Persistent: Identifiers should be expected to work reliably for 10-15 years after they have been assigned.
Unique: Identifiers should be unique, i.e., the same identifier should not be assigned to more than one vocabulary or term in the context of a vocabulary.
Resolvable: All identifiers should be resolvable, i.e., there should be a 'resolution service' that accepts the identifier and returns a URL for a current location of a definition of the vocabulary or term. This definition may use VDEX but need not do so.
Transportable: Vocabularies should be able to move between repositories (locations) without the identifier needing to be changed.
Usable in non-digital environments: Identifiers should be usable in non-Web contexts, i.e., it should be possible to print identifiers in paper articles or dictate them over the phone. For this reason, identifiers should be reasonably short and reasonably intelligible to people.
URI compliant: Identifiers must conform to the URI specification. (Ideally, identifiers should be based on existing standards and technologies - however, they should also be independent of any particular protocol.)
A simplistic approach that may comply with these recommendations may involve using vocabulary identifiers that are identical to a URL where a copy of the vocabulary is maintained and where the URL is in a domain registered to and managed by the owner of the vocabulary. This approach will not be practical in many real-world situations. Non-URL schemes, such as Uniform Resource Names (URNs), may be appropriate. 1EdTech provides some guidance [IMSPLID] in respect of a proposed 1EdTech UID scheme based on URNs. The treatment of the vocabulary terms as the uniquely identified "resource" will probably require more sophisticated treatment for large value domains and the specification of services for resolution, query etc.
2.2 Building Universally Unique Identifiers for Terms
At the start of section 2 it was stated "A term in the context of a value domain may be universally identified through a combination of the identity of the value domain (a universally unique part) and the identity of the term (a locally unique part)." The expression of such a universally unique identifier may occur in two ways:
- By expressing the identifier for the vocabulary and local identifier for the term separately;
- By combining the two identifiers into a single identifier using a well-defined mechanism.
Because the VDEX Information Model and Binding keep the two identifiers separate, option 1 will be most robust. Option 1 should be used in preference to option 2. Option 1 is the approach used in many e-learning specifications and standards - see section 2.3.
For option 2, we define a best practice approach for the two classes of URI: URL and URN (see RFC 2396 and RFC2141). The recommended practices are as follows:
- If the vocabulary identifier has URN syntax then compose a URN for the term in the context of the vocabulary by appending to the vocabulary URN: ":" followed by the vocabulary-local term identifier.
- If the vocabulary identifier has URL syntax then compose a URL for the term in the context of the vocabulary by appending to the vocabulary URL: "#" followed by the vocabulary-local term identifier. This recipe causes us to prohibit URI fragment references in vocabulary identifiers (VDEX Information Model section 2.1).
2.3 Referencing VDEX-Defined Vocabulary Terms
Diverse 1EdTech specifications and IEEE LOM contain elements where controlled terms should be used. These elements are often specified as being of a "vocabulary data type" and a definition of the permitted terms and their usage may be expressed using VDEX. The "flatTokenTerms" profile applies to this case. The content of the vocabulary data type element is generally split into two parts (although the name of the two parts and the nature of their structure in the XML bindings often varies). The two parts are often identified as the value of the term and the source of the term. The "source" should be considered to be equivalent to the identifier of the value domain - the vocabulary identifier in a VDEX instance. The "value" should be the identifier of the term in the value domain (i.e., a permitted value) - i.e., a term identifier in a VDEX instance.
| VDEX Fragment | Reference from Meta-data |
|---|---|
<!--this is not a valid VDEX XML instance-->
<vdex profileType="flatTokenTerms">
<vocabIdentifier>URN:FICTIONAL:1234</vocabIdentifier>
<term>
<termIdentifier>AB</termIdentifier>
<caption>
<langstring language="en">A caption</langstring>
</caption>
</term>
</vdex>
|
<!--this is not a valid 1EdTech Meta-Data XML instance-->
<lom>
<relation>
<kind>
<source>
<langstring>
URN:FICTIONAL:1234
</langstring>
</source>
<value>
<langstring>AB</langstring>
</value>
</kind>
</relation>
</lom>
|
1EdTech Meta-Data and IEEE LOM allow for resource classification using taxonomies. The VDEX profile type "hierarchicalTokenTerms" applies in this case. These meta-data schemas express the classification though a "source" for the classification scheme being used and a "taxon path" where the various "taxon" elements identify a specific classification concept (e.g., a subject). As in the previous case, the "source" maps to the VDEX vocabulary identifier. The "taxon" element contains two parts: an "id" and an "entry". These map to the VDEX term identifier and matching VDEX term caption.
| VDEX Fragment | Reference from Meta-data |
|---|---|
<!--this is not a valid VDEX XML instance-->
<vdex profileType="hierarchicalTokenTerms">
<vocabName>
<langstring language="en">MeSH (National Institute of Health Medical Subject Headings)</langstring>
</vocabName>
<vocabIdentifier>URN:FICTIONAL:MESH</vocabIdentifier>
<term>
<termIdentifier>L01</termIdentifier>
<caption>
<langstring language="en">Information Science</langstring>
</caption>
<term>
<termIdentifier>L01.040</termIdentifier>
<caption>
<langstring language="en">Book Collecting</langstring>
</caption>
</term>
<term>
<termIdentifier>L01.080</termIdentifier>
<caption>
<langstring language="en">Chronology</langstring>
</caption>
</term>
</vdex>
|
<!--this is not a valid 1EdTech Meta-Data XML instance-->
<lom>
<classification>
<taxonpath>
<source>
URN:FICTIONAL:MESH
</source>
<taxon>
<id>L01</id>
<entry>
<langstring language="en">
Information Science
</langstring>
</entry>
<taxon>
<id> L01.040</id>
<entry>
<langstring language="en">
Book Collecting
</langstring>
</entry>
</taxon>
</taxon>
</taxonpath >
</classification >
</lom>
|
3. Best Practices for Creating, Managing, and Using Vocabularies
This specification does not make any recommendation on how vocabularies should be created or managed since there is a great deal of existing practice in this area. In the interests of interoperability and sustainability, however, there are a number of specific standards that should be followed and a number of recommendations of good practice from communities outside 1EdTech that we recommend as informative material.
The best practices that should be followed are as follows:
- ISO 2799 for monolingual thesauri. If ISO 2799 is used in VDEX then the Information Model should be consulted for some mandatory requirements.
- ISO 5964 for multilingual thesauri that require linguistic equivalence terms more complex than 'exact equivalence'. If ISO 5964 is used in VDEX then the Information Model should be consulted for some mandatory requirements.
- Informative material from various sources is listed below. 1EdTech does not specifically recommend any of the practices described in these works but believes that all of these works are from credible academic sources.
- "Controlled Vocabularies for Learning Object Metadata. - Typology, impact analysis, guidelines and a web based Vocabularies Registry". F. Van Assche, L. Anido-Rifón, L. M. Campbell, and M. Willem (see Appendix for status and access).
- "Guidelines for Forming Language Equivalents A Model Based on the Art & Architecture Thesaurus", accessed at http://www.chin.gc.ca/Resources/Publications/Guidelines/English/index.html
- ISO/IEC PDTR 15452, Information technology, Specification of data value domains, Draft 4.0 May 1998, ISO/IEC JTC 1/SC 14, Data Engineering.
- European Learning Resources Thesaurus - European Schoolnet, accessed at http://www.eun.org/goto.cfm?did=7208
4. Implementation Recommendations
4.1 XML Binding
The VDEX XML Binding Specification contains a number of cautions in respect of future changes in XML binding element order and the use of constraints on identifier uniqueness and relationship referential integrity.
4.2 Element-by-Element Recommendations
Only those elements where there is considered to be an implementation guideline to give are listed below.
4.2.1 Vocabulary Identifier
4.2.2 Term Identifier
In cases of vocabularies of human language terms such as thesauri, glossaries or dictionaries then the identifier is assumed to have no significance outside the instance. In these cases, the human language term is the significant information.
Some uses of VDEX may not provide an identifier for the vocabulary and in such cases it will depend on the application whether or not the identifier provided on the terms is meaningful outside the instance.
4.2.3 Caption
For the case when the vocabulary is not a collection of "tokenized terms" but is a collection of human language terms (thesaurus, glossary etc.) then the caption element provides the term to be used. These profile types require there to be a caption and restrict it to only contain a single human language string. If the term is a "tokenized term", where the term identifier stands for a language neutral concept, then any number of equivalent human language captions may be presented to briefly explain the meaning of the concept the term represents.
4.2.4 Media Descriptor
Usage of the Media Descriptor element is conveniently illustrated by an example.
The media descriptor should not be used to convey a digital audio variant of the text of the description element, nor to convey a digital image variant of formatted text etc.
The URL provided to locate the media resource might be a fully qualified URL or a relative URL. The use of xml:base is not recommended by VDEX; implementations making use of this device should document it as an extension. It may be appropriate to consider using 1EdTech Content Packaging for some applications, especially if the media descriptor is actually a collection of separate files.
4.2.5 Relationship
Relationships in VDEX must be explicit about both the terms that are related. The stated relationship is from the term identified as the "source term" and towards the term identified as the "target term". Whether this statement implies a reverse relationship (either symmetric or asymmetric) is not defined by VDEX but arises from the definition of the relationship actually used.
In the case when the source and target terms are identified within the scope of the value domain, the identifier used should be the value of the identifier property of the related terms and should make no mention of the identity of the vocabulary.
In the case when either of the source or target terms must make reference to a term in another vocabulary, then the vocabularyIdentifier attribute (see XML Binding) should be used. VDEX does not say how the referenced vocabulary should be located using its identifier: this is context and implementation dependent.
It is permitted for both the source and target terms in a relationship to be references to 'foreign' vocabularies but this should not be used since it extends the intent of VDEX and may not be understood.
VDEX provides for exact linguistic equivalences by allowing those elements that are "langstrings", such as Caption, to contain multiple entries, each in a different language. The relationship element must not be used for this case.
4.2.6 Meta-data
Meta-data may be included for the vocabulary as a whole or for individual terms. Wherever possible, meta-data that applies to all terms individually or to the vocabulary as an entity should be expressed in meta-data element(s) that are immediate children of <vdex> and additional information that pertains to specific terms should be provided though meta-data element(s) that are immediate children of that <term>. Typical uses are to identify the owner of, or authority for, the vocabulary and version information etc. A particular application profile for VDEX may impose particular restrictions or requirements on the meta-data used in an instance but VDEX itself is entirely neutral as to which meta-data schema is used or which elements may be used within that schema.
The VDEX XML Binding allows for repeated <metadata> elements, each with arbitrary content (see the VDEX XML Binding for restrictions). A separate <metadata> element should be used for each meta-data record that is used but different <metadata> elements may contain:
The meta-data element should not be used as a vehicle for extending the VDEX model; specific extension elements should be used for this purpose. The VDEX Binding explains how the XML Binding of VDEX should be extended.
4.2.7 Langstrings
The value space of the language property of langstrings and the instance default language property is declared as "Language Code". There are a number of international specifications and agreements relating to language codes, including regional/national variations. VDEX Version 1.0 requires that RFC1766 be followed. Implementers should take care to both be aware of the possibility of data being received not precisely conforming to RFC1766 as well as the need to produce conformant language identification. Although this specification mandates conformance to RFC1766 in the current version, we note that it is technically superseded by RFC3066; future versions of VDEX may mandate RFC3066 in due course. The recommendation of a technically obsolete RFC is made on the basis that the schema language used for the XML Binding of VDEX references RFC1766 normatively.
Language subtags are permitted by RFC1766 but should only be used when necessary. For example, "en-US" would be spuriously precise for the word "green" but may be deemed necessary for the word "color". Implementers should consider whether interoperability might be served by providing less precise language codes even in cases when there are regional spelling differences. Degraded precision may be appropriate, for example, when only one regional variation is included.
4.3 Use of VDEX Instances with 1EdTech Content Packaging
If it is desired to convey a VDEX instance as a resource in an 1EdTech Content Package, the approach should follow that described in [IMSBUND], whatever the binding employed. There are two distinct roles envisaged for a VDEX instance contained within a content package and a different resource type string should be used for each, as follows:
In most cases, the application intended for the information will be clear from the context and a type of ims_vdex_xmlv1p0 may be used. The sub-types should be used to reduce uncertainty, hence to promote interoperability. Note 1: a resource with a type of ims_vdex_xmlv1p0/* may also contain media files referenced from the mediaDescriptor element.
Note 2: the syntax for these resource type strings: ims_{spec}_xmlv{n}p{m} follows [IMSBUND] rather than the current XML namespace and XSD file name conventions.
4.4 Complex Vocabularies
VDEX does not set out to be a modelling tool for vocabularies or to support vocabularies of arbitrary complexity. Facility has been made, however, for some non-trivial vocabulary types. This guide will not attempt to survey the range of possibilities but three cases are outlined below to be both informative and also to encourage users with complex use cases to experiment with VDEX.
VDEX has intentionally kept its core model sufficiently simple that the core use cases can be implemented easily and reliably while allowing for some more complex cases to be handled by extension and profiling. Whereas the simple types of vocabulary reflected in the "profile types" defined in the information model should interoperate without the need for parties to define application profiles, the types of vocabulary mentioned below would probably not exchange interoperably without a well-defined application profile.
4.4.1 Facetted Schemes
The VDEX model can handle faceted vocabularies but this requires the definition of appropriate relationships between the faceted nodes and the nodes that make up the facets. We suggest the use of a relationship of "hasFacet" to indicate the facets of a particular node. If necessary, users can use "isFacetOf" to indicate the inverse relationship. The VDEX facility permitting designation of a term as not being valid for indexing may also find applicability in facetted schemes.
4.4.2 Micro-thesauri
Some communities define a collection of terms and separately define a number of small thesauri (micro-thesauri) that make use of subsets of these terms. A term may appear in several micro-thesauri.
Since VDEX holds the definitions of terms and of relationships separately, it is capable of going some way towards the expression of micro-thesauri. While VDEX does not provide a method of grouping statements of relationship into sets, implementers of micro-thesauri could use meta-data or the extension mechanism within the relationship element to accomplish this.
4.4.3 Polyhierarchical Taxonomies
Polyhierarchical taxonomies share with the micro-thesaurus case the property that there is a more complex structure of relationship than can be expressed with a simple hierarchical structure. There are a number of possible polyhierarchical structures but at least some can be adequately expressed in VDEX using the source/target pairs in the relationship, possibly with references to 'foreign' terms using the vocabularyIdentifier attribute (in the XML Binding).
4.5 Extensibility and Related Issues
Extensibility and related issues deals with the concept of modularity, reusability etc.
Implementations making use of extensions to VDEX should be supported by descriptions that clearly identify the function and form of the extensions in order for users of data and software to understand the likely degradation of behavior in systems not supporting the extensions.
4.5.1 Extension of the VDEX Model
The VDEX model is intentionally not a universal modeling language for arbitrary classes of vocabulary. If VDEX does not provide the expressiveness required then the recommended approach is to use VDEX with extensions, preferably agreed in a community of practice. This approach:
- Avoids proliferation of models with a great deal of similarity at a semantic level;
- May allow a user of a system that is ignorant of the extensions to gain some benefit from a degraded but non-zero performance.
The manner of extension is binding-dependent. The VDEX Binding Guide explains how XML 1.0 documents using W3C XML Schema 1.0 can be extended such that graceful degradation of performance is enabled.
4.5.2 Use of the VDEX Model as a Component
Extension of the VDEX model leads to specialization. In some cases, extending the VDEX model may not be tractable or may lead to complex, unworkable or obfuscated cases; whereas extension is preferred it is not required. An alternative to extending VDEX is to use VDEX as a component of a novel model - i.e., as a module. This approach would not normally allow degradation but would, on the other hand, allow software components built for processing VDEX to be reused.
An imaginary information model to describe application profiles might make use of VDEX as a component to define and describe value spaces for certain elements.
4.6 Exchanging Fragments
There are several possible reasons why fragments might be exchanged. The fragment may be:
- Complete in terms of the VDEX Information Model but containing a subset of the terms in a vocabulary.
- Incomplete in terms of the VDEX Information Model. This could be a single term.
Either of these types of fragment might be useful if, for example:
- Programmatic exchange of data (for example in a service oriented architecture) occurs
- VDEX is used in a modular way as a component of a more complex information model.
The description of the use of relationship in section 4.2.5 should be born in mind whenever fragments are considered.
4.7 Tracking Changes in Evolving Vocabularies
In the vocabulary world it appears to be common to accrete all old terms into new drafts of a thesaurus rather than versioned in the traditional computer science sense, with one draft replacing another. Versioning is achieved since the terms include meta-data to indicate which are the currently valid terms, and at what points in time obsolete terms were valid. Thus, each successive draft contains all information that was in the previous draft, even if that information has been superseded. The information that is not currently valid references the currently valid information, and vice versa, to show appropriate usage and to aid translation.
We suggest that users use meta-data and relationships to track changes:
- track the dates that a particular term was valid by using user-defined meta-data;
- use relationships of "supersedes" and "isSupersededBy" to show the evolution of terms over time.
5. Examples
This section includes full examples. All have been validated, against restrictive and full XSD, using:
All examples use an appropriate profile type and refer to the relevant restrictive XSD.
5.1 Instances of VDEX
5.1.1 The ISO Thesaurus Relations Expressed as a Flat List of Tokens
This is an XML Binding of the vocabulary specified in the VDEX 1.0 Information Model document. It includes a short piece of meta-data to identify ISO2788 as being the originator of the terms and a vocabulary identifier URI within the 1EdTech Consortium internet domain. This instance only uses English for the language strings so we use the language attribute at the root element, <vdex>.
The meta-data provided in this example uses the 1EdTech Learning Resource Meta-Data v1.2. This specification made reference to the vocabularies specified in a draft of IEEE LOM, hence the <source> element identifies the vocabulary as being "LOMv1.0".
<?xml version="1.0" encoding="UTF-8"?>
<vdex xmlns="http://www.imsglobal.org/xsd/imsvdex_v1p0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.imsglobal.org/xsd/imsvdex_v1p0 imsvdex_v1p0.xsd http://www.imsglobal.org/xsd/imsmd_rootv1p2p1 imsmd_rootv1p2p1.xsd" orderSignificant="false" profileType="flatTokenTerms" language="en">
<vocabName>
<langstring>ISO 2788 Term Relationships for Monolingual Thesauri as Used by the 1EdTech Vocabulary Definition Exchange Specification</langstring>
</vocabName>
<vocabIdentifier>http://www.imsglobal.org/vocabularies/iso2788_relations.xml</vocabIdentifier>
<term>
<termIdentifier>USE</termIdentifier>
<caption>
<langstring>use</langstring>
</caption>
<description>
<langstring>Preferred term when a choice between synonyms or quasi-synonyms exists. </langstring>
</description>
</term>
<term>
<termIdentifier>UF</termIdentifier>
<caption>
<langstring>use for</langstring>
</caption>
<description>
<langstring>Non-preferred synonym or quasi-synonym for the term being described. </langstring>
</description>
</term>
<term>
<termIdentifier>TT</termIdentifier>
<caption>
<langstring>top term</langstring>
</caption>
<description>
<langstring>Broadest class to which the specific term belongs. </langstring>
</description>
</term>
<term>
<termIdentifier>BT</termIdentifier>
<caption>
<langstring>broader term</langstring>
</caption>
<description>
<langstring>Term that has a broader meaning than the term being described. </langstring>
</description>
</term>
<term>
<termIdentifier>NT</termIdentifier>
<caption>
<langstring>narrower term</langstring>
</caption>
<description>
<langstring>Term that has a narrower meaning than the term being described. </langstring>
</description>
</term>
<term>
<termIdentifier>RT</termIdentifier>
<caption>
<langstring>related term</langstring>
</caption>
<description>
<langstring>Term related to the one being described. </langstring>
</description>
</term>
<metadata>
<lom xmlns="http://www.imsglobal.org/xsd/imsmd_rootv1p2p1">
<relation>
<kind>
<source>
<langstring>LOMv1.0</langstring>
</source>
<value>
<langstring>IsBasedOn</langstring>
</value>
</kind>
<resource>
<description>
<langstring>ISO 2788:1986 - Guidelines for the establishment and development of monolingual thesauri</langstring>
</description>
</resource>
</relation>
</lom>
</metadata>
</vdex>
5.1.2 A Short Glossary of Eye-Related Terms
The definitions used are from http://www.glaucoma.org/learn/glossary.html. This example could usefully be extended to use the mediaDescriptor element to link to images that clarify the definitions. In this case, the term identifiers are not globally significant but provide internal handles. There is no identifier for the glossary as a whole although this might often be present since a glossary is an identifiable resource.
<?xml version="1.0" encoding="UTF-8"?>
<!-- Definitions from http://www.glaucoma.org/learn/glossary.html -->
<vdex profileType="glossaryOrDictionary" xmlns="http://www.imsglobal.org/xsd/imsvdex_v1p0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.imsglobal.org/xsd/imsvdex_v1p0 imsvdex_v1p0.xsd" orderSignificant="false" language="en">
<vocabName>
<langstring>Glossary of Terms Relevant to Glaucoma</langstring>
</vocabName>
<term>
<termIdentifier>glaucoma1</termIdentifier>
<caption>
<langstring>angle closure glaucoma</langstring>
</caption>
<description>
<langstring>A type of glaucoma caused by a sudden and severe rise in eye pressure. Occurs when the pupil enlarges too much or too quickly, and the outer edge of the iris blocks the eye's drainage canals. Can be either acute or chronic.</langstring>
</description>
</term>
<term>
<termIdentifier>glaucoma2</termIdentifier>
<caption>
<langstring>aqueous humor</langstring>
</caption>
<description>
<langstring>The fluid made in the front part of the eye.</langstring>
</description>
</term>
<term>
<termIdentifier>glaucoma3</termIdentifier>
<caption>
<langstring>bleb</langstring>
</caption>
<description>
<langstring>A bubble in the eye tissue that lays over the new drainage opening created during surgery.</langstring>
</description>
</term>
<term>
<termIdentifier>glaucoma4</termIdentifier>
<caption>
<langstring>4-FU</langstring>
</caption>
<description>
<langstring>A medication designed to stop the healing process. Sometimes used around the bleb to stop it from healing or scarring over.</langstring>
</description>
</term>
<term>
<termIdentifier>glaucoma5</termIdentifier>
<caption>
<langstring>central vision</langstring>
</caption>
<description>
<langstring>What is seen when you look straight ahead or when you read.</langstring>
</description>
</term>
</vdex>
5.1.3 A Fragment of the MeSH Taxonomy
Information from US National Library of Medicine Medical Subject Headings, http://www.nlm.nih.gov/mesh/meshhome.html. This fragment does not start at the root of the MeSH taxonomy and is a fragment from MeSH, both horizontally and vertically in the taxonomy. A more complete fragment, of the L01 branch, is available as a download example.
In this example, there are no helpful descriptions; only the identifiers and associated subject headings are encoded. This would be sufficient to completely populate the classification container in an 1EdTech Meta-Data or IEEE LOM instance but does not really contain the additional scope note information that someone might need to correctly apply a classification.
NB: The vocabulary identifier is not official.
<?xml version="1.0" encoding="UTF-8"?>
<vdex orderSignificant="false" profileType="hierarchicalTokenTerms" language="en" xsi:schemaLocation="http://www.imsglobal.org/xsd/imsvdex_v1p0 imsvdex_v1p0.xsd" xmlns="http://www.imsglobal.org/xsd/imsvdex_v1p0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<vocabName>
<langstring>MeSH (National Institute of Health Medical Subject Headings)</langstring>
</vocabName>
<vocabIdentifier>http://www.fdgroup.com/~ftpkod/kmap/mesh_v1p0.xml</vocabIdentifier>
<term>
<termIdentifier>L01</termIdentifier>
<caption>
<langstring>Information Science</langstring>
</caption>
<term>
<termIdentifier>L01.040</termIdentifier>
<caption>
<langstring>Book Collecting</langstring>
</caption>
</term>
<term>
<termIdentifier>L01.080</termIdentifier>
<caption>
<langstring>Chronology</langstring>
</caption>
</term>
<term>
<termIdentifier>L01.100</termIdentifier>
<caption>
<langstring>Classification</langstring>
</caption>
</term>
<term>
<termIdentifier>L01.143</termIdentifier>
<caption>
<langstring>Communication</langstring>
</caption>
<term>
<termIdentifier>L01.143.050</termIdentifier>
<caption>
<langstring>Advertising</langstring>
</caption>
</term>
<term>
<termIdentifier>L01.143.230</termIdentifier>
<caption>
<langstring>Communication Barriers</langstring>
</caption>
</term>
<term>
<termIdentifier>L01.143.283</termIdentifier>
<caption>
<langstring>Cybernetics</langstring>
</caption>
<term>
<termIdentifier>L01.143.283.425</termIdentifier>
<caption>
<langstring>Feedback</langstring>
</caption>
</term>
</term>
</term>
</term>
</vdex>
5.1.4 A Fragment of a Thesaurus Using the ISO Relationships and Referencing the First Example
This example shows how an element with a vocabulary data type makes reference to a VDEX-defined vocabulary. In this case the relationshipType element is of vocabulary data type but the same strategy applies to vocabulary data types in 1EdTech specifications and IEEE LOM in general, although the binding of the source and value pair is often as separate sub-elements in most current 1EdTech specifications. In this example, the language is declared for each <langstring>.
<?xml version="1.0" encoding="UTF-8"?>
<vdex orderSignificant="false" profileType="thesaurus" xsi:schemaLocation="http://www.imsglobal.org/xsd/imsvdex_v1p0 imsvdex_v1p0.xsd" xmlns="http://www.imsglobal.org/xsd/imsvdex_v1p0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<vocabName>
<langstring language="en">An example thesaurus fragment</langstring>
</vocabName>
<term>
<termIdentifier>MONOTH_00001</termIdentifier>
<caption>
<langstring language="en">ACOUSTIC BARRIERS</langstring>
</caption>
</term>
<term>
<termIdentifier>MONOTH_00002</termIdentifier>
<caption>
<langstring language="en">ACOUSTIC INSULATION</langstring>
</caption>
</term>
<term>
<termIdentifier>MONOTH_00003</termIdentifier>
<caption>
<langstring language="en">ACOUSTIC PHONETICS</langstring>
</caption>
<description>
<langstring language="en">
Study of the physical properties of speech sounds during
transmission and as the are heard by the listener</langstring>
</description>
</term>
<relationship>
<sourceTerm>MONOTH_00001</sourceTerm>
<targetTerm>MONOTH_00002</targetTerm>
<relationshipType source="http://www.imsglobal.org/vocabularies/iso2788_relations.xml">USE</relationshipType>
</relationship>
<relationship>
<sourceTerm>MONOTH_00002</sourceTerm>
<targetTerm>MONOTH_00001</targetTerm>
<relationshipType source="http://www.imsglobal.org/vocabularies/iso2788_relations.xml">UF</relationshipType>
</relationship>
</vdex>
5.1.5 A Fragment of a Fictional Multilingual Thesaurus
This example does not necessarily reflect good practice as defined by ISO 5964 but illustrates use of two schemes of relationship type to create a map of monolingual thesaurus relationships between two sets of terms, one English and one Spanish, as well as translation mappings from equivalent terms in each language. Note that in this example, each term has only one <langstring>; each language must reside in separate terms to permit the full range of translation equivalence type relationships.
NB: the use of thesaurus for the profile type should only be used when the data could meaningfully be described as being a thesaurus: thesaurus should not be used for arbitrary relationship maps.
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<vdex orderSignificant="false" profileType="thesaurus" xsi:schemaLocation="http://www.imsglobal.org/xsd/imsvdex_v1p0 imsvdex_v1p0.xsd" xmlns="http://www.imsglobal.org/xsd/imsvdex_v1p0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<vocabName>
<langstring language="en">An example bilingual thesaurus fragment using exact equivalences - the world</langstring>
</vocabName>
<term>
<termIdentifier>W</termIdentifier>
<caption>
<langstring language="en">world</langstring>
<langstring language="es">mundo</langstring>
</caption>
</term>
<term>
<termIdentifier>EU</termIdentifier>
<caption>
<langstring language="en">Europe</langstring>
<langstring language="es">Europa</langstring>
</caption>
</term>
<term>
<termIdentifier>ES</termIdentifier>
<caption>
<langstring language="en">Spain</langstring>
<langstring language="es">España</langstring>
</caption>
</term>
<term>
<termIdentifier>GB</termIdentifier>
<caption>
<langstring language="en">Great Britain</langstring>
<langstring language="es">Gran Bretaña</langstring>
</caption>
</term>
<relationship>
<sourceTerm>W</sourceTerm>
<targetTerm>EU</targetTerm>
<relationshipType source="http://www.imsglobal.org/vocabularies/iso2788_relations.xml">NT</relationshipType>
</relationship>
<relationship>
<sourceTerm>EU</sourceTerm>
<targetTerm>ES</targetTerm>
<relationshipType source="http://www.imsglobal.org/vocabularies/iso2788_relations.xml">NT</relationshipType>
</relationship>
<relationship>
<sourceTerm>EU</sourceTerm>
<targetTerm>GB</targetTerm>
<relationshipType source="http://www.imsglobal.org/vocabularies/iso2788_relations.xml">NT</relationshipType>
</relationship>
<relationship>
<sourceTerm>EU</sourceTerm>
<targetTerm>W</targetTerm>
<relationshipType source="http://www.imsglobal.org/vocabularies/iso2788_relations.xml">BT</relationshipType>
</relationship>
<relationship>
<sourceTerm>GB</sourceTerm>
<targetTerm>EU</targetTerm>
<relationshipType source="http://www.imsglobal.org/vocabularies/iso2788_relations.xml">BT</relationshipType>
</relationship>
<relationship>
<sourceTerm>ES</sourceTerm>
<targetTerm>EU</targetTerm>
<relationshipType source="http://www.imsglobal.org/vocabularies/iso2788_relations.xml">BT</relationshipType>
</relationship>
</vdex>
5.1.6 A Fragment of a Multilingual Flat List of Tokens
Note that in this case, unlike the previous multilingual thesaurus example, each term contains all of the equivalent <langstring> elements. This is because they are captions for a concept that is defined by the combination of the vocabulary identifier and the term identifier. These two identifiers would provide the source and value pair for a vocabulary data type element using this particular value space.
This data is from European Schoolnet, European Learning Resources Thesaurus Multilingual vocabulary for learning situation, http://www.eun.org/etb/voc/pedagogical.pdf
<?xml version="1.0" encoding="UTF-8"?>
<vdex xmlns="http://www.imsglobal.org/xsd/imsvdex_v1p0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.imsglobal.org/xsd/imsvdex_v1p0 imsvdex_v1p0.xsd http://www.imsglobal.org/xsd/imsmd_rootv1p2p1 imsmd_rootv1p2p1.xsd" orderSignificant="false" profileType="flatTokenTerms" language="en">
<vocabName>
<langstring language="en">ETB - Teaching Methods</langstring>
<langstring language="es">ETB - Métodos de enseñanza</langstring>
<langstring language="el">ETB - ìÝèïäïé äéäáóêáëßáò</langstring>
<!-- this is only a fragment -->
</vocabName>
<vocabIdentifier>http://www.eun.org/etb/voc/pedagogical.doc#teaching_methods</vocabIdentifier>
<term>
<termIdentifier>brainstorm</termIdentifier>
<caption>
<langstring language="en">Brainstorming</langstring>
<langstring language="es">Brainstorming</langstring>
<langstring language="el">åëåýèåñç óõæÞôçóç</langstring>
</caption>
</term>
<term>
<termIdentifier>CAI</termIdentifier>
<caption>
<langstring language="en">Computer assisted instruction</langstring>
<langstring language="es">Enseñanza asistida por ordenador</langstring>
<langstring language="el">äéäáóêáëßá ìå ôçí âïÞèåéá õðïëïãéóôÞ</langstring>
</caption>
</term>
<term>
<termIdentifier>cooperativeLearning</termIdentifier>
<caption>
<langstring language="en">Cooperative learning</langstring>
<langstring language="es">Aprendizaje cooperativo</langstring>
<langstring language="el">óõíåñãáôéêÞ ìÜèçóç</langstring>
</caption>
</term>
<term>
<termIdentifier>demonstrations</termIdentifier>
<caption>
<langstring language="en">Demonstrations</langstring>
<langstring language="es">Demostraciones</langstring>
<langstring language="el">ÐáñáäåéãìáôéêÞ äéäáóêáëßá</langstring>
</caption>
</term>
<metadata>
<lom xmlns="http://www.imsglobal.org/xsd/imsmd_rootv1p2p1">
<relation>
<kind>
<source>
<langstring>LOMv1.0</langstring>
</source>
<value>
<langstring>IsBasedOn</langstring>
</value>
</kind>
<resource>
<description>
<langstring>European Schoolnet, European Treasury Browser - Multilingual vocabulary for learning situation, http://www.eun.org/etb/voc/pedagogical.doc</langstring>
</description>
</resource>
</relation>
<relation>
<kind>
<source>
<langstring>LOMv1.0</langstring>
</source>
<value>
<langstring>IsBasedOn</langstring>
</value>
</kind>
<resource>
<description>
<langstring>GEM LearningSituation Original vocabulary translated in 7 languages for ETB </langstring>
</description>
</resource>
</relation>
</lom>
</metadata>
</vdex>
5.1.7 An Fragment of the IEEE LOM Vocabulary
This example is not sanctioned by IEEE but shows how VDEX could be used to express the vocabularies in the IEEE 1484-12.1-2002 (LOM) standard. The terms are collected together under headings that are not valid for indexing; the collections each correlate with a LOM element where the terms may be used.
<?xml version="1.0" encoding="UTF-8"?>
<vdex orderSignificant="false" profileType="hierarchicalTokenTerms" language="en" xsi:schemaLocation="http://www.imsglobal.org/xsd/imsvdex_v1p0 imsvdex_v1p0.xsd" xmlns="http://www.imsglobal.org/xsd/imsvdex_v1p0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<vocabName>
<langstring>IEEE LOM v1.0 Vocabularies</langstring>
</vocabName>
<vocabIdentifier>URN:FICTIONAL:this_is_not_IEEE_approved</vocabIdentifier>
<!-- this is a fraction of the LOM vocabularies for the purposes of illustrating 1EdTech VDEX 1.0 -->
<term validIndex="false">
<termIdentifier>aggregationLevel</termIdentifier>
<caption>
<langstring>Aggregation Level Descriptors</langstring>
</caption>
<term>
<termIdentifier>1</termIdentifier>
<caption>
<langstring> the smallest level of aggregation, e.g., raw media data or fragments.</langstring>
</caption>
</term>
<term>
<termIdentifier>2</termIdentifier>
<caption>
<langstring>a collection of level 1 learning objects, e.g., a lesson</langstring>
</caption>
</term>
<term>
<termIdentifier>3</termIdentifier>
<caption>
<langstring>a collection of level 2 learning objects, e.g., a course.</langstring>
</caption>
</term>
<term>
<termIdentifier>4</termIdentifier>
<caption>
<langstring> the largest level of granularity, e.g., a set of courses that lead to a certificate. Level 4 objects can contain level 3 objects, or can recursively contain other level 4 objects.</langstring>
</caption>
</term>
</term>
<term validIndex="false">
<termIdentifier>learningResourceType</termIdentifier>
<caption>
<langstring>Learning Resource Types</langstring>
</caption>
<term>
<termIdentifier>excercise</termIdentifier>
<caption>
<langstring>exercise</langstring>
</caption>
</term>
<!-- further members of the Learning Resource Type vocabulary -->
</term>
</vdex>
5.2 Other Examples
5.2.1 Using VDEX as a Content Type in an 1EdTech Content Package
The resource type attribute contains sufficient information to allow a system to accept, ignore or reject the data. An accepting system may choose to present or process the data in diverse and unspecified ways. One approach might be to present a pull-down for a learner like Glossaries>Eye Glossaries>Glaucoma Glossary>aqueous humor to cause a pop up to be launched containing the definition and supporting image (this example assumes mediaDescriptor is used to extend example 5.1.2.
<?xml version="1.0" encoding="UTF-8"?>
<manifest identifier="MANIFEST1" xmlns="http://www.imsglobal.org/xsd/imscp_v1p1" xmlns:imsmd="http://www.imsglobal.org/xsd/imsmd_v1p2" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.imsglobal.org/xsd/imscp_v1p1 imscp_v1p1.xsd">
<metadata/>
<organizations default="TOC1">
<organization identifier="TOC1" structure="hierarchical">
<title>Eye Glossaries</title>
<item identifier="ITEM1" identifierref="RESOURCE1">
<title>Glaucoma Glossary</title>
</item>
</organization>
</organizations>
<resources>
<resource identifier="RESOURCE1" type="ims_vdex_xmlv1p0/content" href="=vdex.xml">
<file href="vdex.xml"/>
<file href="glaucoma1.jpg"/>
<file href="glaucoma2.jpg"/>
<file href="glaucoma3.jpg"/>
<file href="glaucoma4.jpg"/>
<file href="glaucoma5.jpg"/>
<file href="glaucoma6.jpg"/>
</resource>
</resources>
</manifest>
5.2.2 Using Meta-Data with VDEX Instances
Sections 5.1.1 and 5.1.6 show examples of using an existing 1EdTech Meta-Data schema with VDEX. This is not a specific recommendation; the Vocabulary Definition Exchange Specification Best Practices and Implementation Guide does not make any statements about which meta-data schema should be used. A further specific caution is that 1EdTech is likely to deprecate use of its Meta-Data specification in favor of IEEE 1484-12.1-2002: Standard for Learning Object Metadata (IEEE LOM) and an IEEE XML binding of this standard when it becomes available.
6. Application Scenarios
This section provides descriptions of some potential applications of the 1EdTech Vocabulary Definition Exchange. It is meant to help readers gain an understanding of the range of uses to which VDEX may be put and to provide the initial ideas to help people apply VDEX to their problems. The scenarios are not meant to imply and degree of constraint.
Actors are italicized. The role of the 1EdTech Vocabulary Exchange is emboldened.
6.1 Automating Meta-Data Editor User Interfaces
6.1.1 Goal
The implementer of a user interface for a meta-data editor wants to provide her users with only human readable choices for vocabulary data elements, because the tokens used in the vocabulary do not correspond to the terminology used by normal human beings in the target user group.
6.1.2 Scenario
Usability studies have also shown that the users tend to make incorrect choices because of ambiguity in the meaning of the choices. Therefore the implementer wants to display an explanation next to the choice, with the explanation changing dynamically to match the current choice.
The figure below (screen shot from an actual interface) shows what the user interface looks like with simple True/False choices:
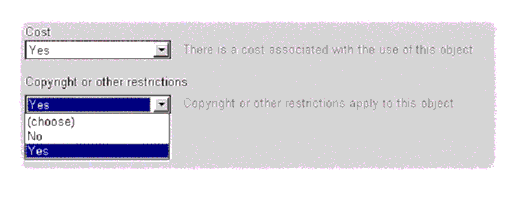
The implementer of the meta-data editor knows however that vocabularies do evolve with different versions of the standards, and that the repository administrators may choose one particularly over another when the user interface is presented to users. The implementer wants to automate the presentation so that no recoding of the user interface is necessary when another vocabulary is chosen for a particular data element, or the vocabulary is updated. The update should only require pointing to a new vocabulary definition. For example, if more choices might be added to the "Cost" vocabulary, say the tokens "saitpas" and "apeutchanger". By using a vocabulary definition that complies with 1EdTech Vocabulary Exchange, the human readable terms "No information" and "Subject to change" defined in the instance as English terms for the new tokens as well as the descriptions provided are automatically added to the user interface.
6.2 Meta-Data Creation Using an Application Profile
6.2.1 Goal
A meta-data creator wishes to create a meta-data record that follows some cataloging guidelines that specify:
- A specific subject classification scheme;
- A specific vocabulary for the intended end user;
- A list of preferred keywords.
6.2.2 Scenario
- The meta-data creator starts up their customizable meta-data creation tool to create meta-data for a learning object in the 1EdTech Meta-Data v1.2 schema.
- They use the tool options to locate from their hard drive 1EdTech Vocabulary Exchange XML documents for the subject classification scheme, intended end user role vocabulary and preferred keywords list. They do this in the context of specific meta-data fields for each one.
- Within the meta-data creation tool the meta-data creator:
- browses up and down the subject classification scheme around the area relevant to the learning object, consulting the notes on scope and application provided in the XML, and selects the most appropriate
- picks an intended end user role from a pull-down list
- types in various keywords and checks they are from the preferred list
- The meta-data creation tool automatically, and invisibly to the user, inserts:
- the complete taxonpath, including id and entry for all taxons and the taxonomy source
- the source and value pair for the intended end user role
- keywords, including country variants (e.g., organise, organize)
6.2.3 Scenario Variant
As for the first scenario but an as-yet-unspecified XML exchange mechanism for application profiles enables a less expert user to plug in the complete set of vocabularies and have them associated with the correct meta-data fields in one simple action.
6.3 Interpreting Meta-Data
6.3.1 Goal
A searcher uses a repository to locate a useful resource using meta-data to define a query and to select good candidates for access.
6.3.2 Scenario
- The searcher goes to an online repository of physics revision learning objects for university students
- The searcher uses the subject browse mechanism, checking out the meaning of some subject headings as they go. This was obtained by the repository operator from an expert (e.g., The Institute of Physics) using the 1EdTech Vocabulary Exchange and contains descriptive notes for each taxon.
- The searcher clicks "show all resources for this subject"
- The repository locates meta-data records and translates all of the tokens (source+value) into more friendly forms (i.e., into the user's language) using its compilation of sourced vocabularies that have been discovered, were supplied when resources were added, or were from the set of vocabularies initially provided with the repository.
- The searcher receives a response expressed in intelligible language.
6.4 Supplying the Learner with a Glossary
6.4.1 Goal
A learner, with a unique personal set of courses and modules, accesses a relevant glossary when working in their LMS.
6.4.2 Scenario
- Packages of learning materials are installed into the LMS using 1EdTech Content Packaging including resources expressed as 1EdTech Vocabulary Exchange XML to express a glossary relevant to each package.
- The learner clicks "glossary | show all" from the main LMS menu.
- The learner views an alphabetically sorted and searchable glossary applicable to all the modules/courses they are using.
6.5 Locating an Appropriate Vocabulary
6.5.1 Goal
A resource creator seeks to reuse existing vocabularies to express information about the resource that they are about to publish.
6.5.2 Scenario
- The resource creator visits the CEN/ISSS LTWS repository of vocabularies to look for appropriate ways to express educational context for some multilingually-subtitled SMIL resources.
- They browse to the educational context section and see entries for various locales.
- They select checkboxes for english, scottish, french and spanish and click "download".
- The resource creator saves the vocabularies in 1EdTech Vocabulary Exchange XML form to their hard drive for installation into their meta-data tool (see Use Case #1).
6.6 Using a Thesaurus Service
6.6.1 Goal
A repository uses a thesaurus web service to provide smart behavior when a searcher looks for a resource.
6.6.2 Scenario
- A community of interest (for example the US DoD) has published a thesaurus, using ISO-2788 relationship types, using 1EdTech Vocabulary Exchange specification.
- Various distributed locations operate a thesaurus web service using this data to easily follow version changes and ensure uniformity
- A searcher uses a keyword to search for resources in a repository
- The repository consults the thesaurus web service to obtain related terms asynchronously while it conducts its own search. The exchange between the two services uses 1EdTech Vocabulary Exchange to transfer the relevant (dynamically created) fragment of the thesaurus.
- The repository returns a list of "hits" to the searcher for the current search term and a list of preferred, "see also", narrower and broader terms if found.
- The searcher uses the list of related terms to easily redefine their search using terms appropriate to the community of interest.
7. Master Reference Files for 1EdTech Specification Vocabularies
Vocabularies included in the 1EdTech VDEX specification are made available at http://www.imsglobal.org/vocabularies/ in VDEX format. The files are iso2278_relations.xml and iso5064_equivalences.xml.
The vocabulary identifier URI is the URL where this file is located
Future 1EdTech specifications or versions where vocabularies are defined will probably follow the same convention.
At the current moment in time, there is no agreed protocol in place for the following cases:
- what happens if either the vocabulary undergoes a version change or VDEX undergoes a version change. In either case, it must be possible to refer to a persistent copy of a specific version.
- what happens if new language captions are added. Is this a new version. Ideally, there should be one master reference for all languages.
Appendix A - Additional Resources
Controlled Vocabularies for Learning Object Metadata. - Typology, impact analysis, guidelines and a web based Vocabularies Registry". F. Van Assche, L. Anido-Rifón , L. M. Campbell and M. Willem, CEN/ISSS Learning Technologies Workshop, DRAFT, http://office.eun.org/kms/sites/cenisss/index.html
IEEE 1484-12.1-2002: Standard for Learning Object Metadata (LOM)
The IEEE 1484-12.1-2002: Standard for Learning Object Metadata can be obtained from IEEE: http://www.ieee.org
The W3C XML Schema 1.0 Control Document, imsrdceo_rootv1p0.xsd, is located at: http://www.imsglobal.org/xsd/imsrdceo_rootv1p0.xsd
Using 1EdTech Content Packaging to Package Instances of LIP and Other 1EdTech Specifications, [IMSBUND]
http://www.imsglobal.org/implementationhandbook/imspack_handv1p0.html
1EdTech Persistent, Location-Independent, Resource Identifier Implementation Handbook version 1.0, [IMSPLID]
http://www.imsglobal.org/implementationhandbook/imsrid_handv1p0.html
1EdTech Persistent, Location-Independent, Resource Identifier Implementation Handbook version 1.0, [IMSPLID]
http://www.imsglobal.org/implementationhandbook/imsrid_handv1p0.html
W3C Architecture Domain, Naming and Addressing: URIs, URLs, ..., http://www.w3.org/Addressing
PURL (Persistent Uniform Resource Locator), http://purl.org
Corporation for National Research Initiatives, Handle System, http://www.handle.net
Digital Object Identifier System, http://www.doi.org/
The PURL-based Object Identifier (draft at 29-May-2003), http://www.ukoln.ac.uk/distributed-systems/poi/
ISO (International Organization for Standardization)
ISO 2788:1986, Guidelines for the establishment and development of monolingual thesauri.
ISO 5964:1985, Guidelines for the establishment and development of multilingual thesauri.
ISO/IEC 10646-1993 (E). Information technology -- Universal Multiple-Octet Coded Character Set (UCS) -- Part 1: Architecture and Basic Multilingual Plane. [Geneva]: International Organization for Standardization, 1993 (plus amendments AM 1 through AM 7). Updated as 10646-2000.
ISO 11404, Language-independent Datatypes, http://www.iso.ch/cate/d19346.html
RFC 1648, A URN namespace for IETF documents, http://www.ietf.org/rfc/rfc1648.txt
RFC 1766, Tags for the Identification of Languages, http://www.ietf.org/rfc/rfc1766.txt
(the IETF considers this to now be obsoleted by RFC 3066)
RFC 2044, UTF-8, a transformation format of Unicode and ISO 10646, http://www.ietf.org/rfc/rfc2044.txt
RFC 2141, URN Syntax, http://www.ietf.org/rfc/rfc2141.txt
RFC 2396, Uniform Resource Identifiers (URI): Generic Syntax, http://www.ietf.org/rfc/rfc2396.txt
RFC 3066, Tags for the Identification of Languages, http://www.ietf.org/rfc/rfc3066.txt
The Unicode Consortium. The Unicode Standard, Version 2.0. Reading, Mass.: Addison-Wesley Developers Press, 1996.
XML Schema Part 0: Primer, W3C Recommendation, 2 May 2001: http://www.w3.org/TR/xmlschema-0/
XML Schema Part 1: Structures, W3C Recommendation, 2 May 2001: http://www.w3.org/TR/xmlschema-1/
XML Schema Part 2: Datatypes, W3C Recommendation, 2 May 2001: http://www.w3.org/TR/xmlschema-2/
XML Version 1.0 Specification of the W3C: http://www.w3.org/TR/1998/REC-xml-19980210
XML Namespace Recommendation of W3C: http://www.w3.org/TR/1999/REC-xml-names-19990114
About This Document
| Title | 1EdTech Vocabulary Definition Exchange Best Practice and Implementation Guide |
| Editor | Adam Cooper |
| Version | 1.0 |
| Version Date | 23 February 2004 |
| Status | Final Specification |
| Summary | This document describes the Vocabulary Definition Exchange Best Practice and Implementation Guide |
| Revision Information | February 2004 |
| Purpose | Defines the VDEX Best Practice and Implementation Guide |
| Document Location | http://www.imsglobal.org/vdex/vdexv1p0/imsvdex_bestv1p0.html |
| To register any comments about the VDEX specification, please visit: http://www.imsglobal.org/developers/ims/imsforum/categories.cfm?catid=18 |
List of Contributors
The following individuals contributed to the development of this document:
| Name | Organization |
|---|---|
| Adam Cooper | FD Learning |
| Claude Ostyn | Click2learn, Inc. |
| Michael Pelikan | Penn State University |
| Brendon Towle | Thomson NETg |
Revision History
Index
A
architecture 1
I
identifier 1, 2, 3, 4, 5, 6, 7, 8, 9, 10
1EdTech Vocabulary Exchange 1, 2, 3
interoperability 1, 2, 3
ISO 1, 2, 3, 4, 5
L
LMS 1, 2
LOM 1, 2, 3, 4, 5, 6, 7, 8, 9
M
meta-data 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12
P
Persistent 1, 2
persistent 1, 2
R
repository 1, 2, 3
resource 1, 2, 3, 4, 5, 6, 7, 8
T
taxonomies 1, 2, 3
term 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11
thesauri 1, 2, 3, 4, 5
thesaurus 1, 2, 3, 4, 5, 6
tokens 1, 2, 3
U
URL 1, 2, 3, 4, 5
URN 1, 2, 3
V
valid 1, 2, 3
vocabulary 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14
1EdTech Consortium, Inc. ("1EdTech") is publishing the information contained in this 1EdTech Vocabulary Definition Exchange Best Practice and Implementation Guide ("Specification") for purposes of scientific, experimental, and scholarly collaboration only.
1EdTech makes no warranty or representation regarding the accuracy or completeness of the Specification.
This material is provided on an "As Is" and "As Available" basis.
The Specification is at all times subject to change and revision without notice.
It is your sole responsibility to evaluate the usefulness, accuracy, and completeness of the Specification as it relates to you.
1EdTech would appreciate receiving your comments and suggestions.
Please contact 1EdTech through our website at http://www.imsglobal.org
Please refer to Document Name: 1EdTech Vocabulary Definition Exchange Best Practice and Implementation Guide Revision: 23 February 2004
