 |
1EdTech Meta-data Best Practice Guide for IEEE 1484.12.1-2002 Standard for Learning Object Metadata Version 1.3 Final Specification |
Copyright © 2006 1EdTech Consortium, Inc. All Rights Reserved.
The 1EdTech Logo is a registered trademark of 1EdTech/GLC
Document Name: 1EdTech Meta-data Best Practice Guide for IEEE 1484.12.1-2002 Standard for Learning Object Metadata
Revision: 31 August 2006
| Date Issued: | 31 August 2006 |
| Latest version: | http://www.imsglobal.org/metadata/mdv1p3/imsmd_bestv1p3.html |
| Description: | Resolves the drift between the 1EdTech Meta-data and the IEEE LOM standard, which began as a combination of 1EdTech Meta-data and ARIADNE collaboration. |
|
IPR and Distribution Notices Recipients of this document are requested to submit, with their comments, notification of any relevant patent claims or other intellectual property rights of which they may be aware that might be infringed by any implementation of the specification set forth in this document, and to provide supporting documentation. 1EdTech takes no position regarding the validity or scope of any intellectual property or other rights that might be claimed to pertain to the implementation or use of the technology described in this document or the extent to which any license under such rights might or might not be available; neither does it represent that it has made any effort to identify any such rights. Information on 1EdTech's procedures with respect to rights in 1EdTech specifications can be found at the 1EdTech Intellectual Property Rights web page: http://www.imsglobal.org/ipr/imsipr_policyFinal.pdf. Copyright © 2006 1EdTech Consortium. All Rights Reserved. Permission is granted to all parties to use excerpts from this document as needed in producing requests for proposals. Use of this specification to develop products or services is governed by the license with 1EdTech found on the 1EdTech website: http://www.imsglobal.org/license.html. The limited permissions granted above are perpetual and will not be revoked by 1EdTech or its successors or assigns. THIS SPECIFICATION IS BEING OFFERED WITHOUT ANY WARRANTY WHATSOEVER, AND IN PARTICULAR, ANY WARRANTY OF NONINFRINGEMENT IS EXPRESSLY DISCLAIMED. ANY USE OF THIS SPECIFICATION SHALL BE MADE ENTIRELY AT THE IMPLEMENTER'S OWN RISK, AND NEITHER THE CONSORTIUM, NOR ANY OF ITS MEMBERS OR SUBMITTERS, SHALL HAVE ANY LIABILITY WHATSOEVER TO ANY IMPLEMENTER OR THIRD PARTY FOR ANY DAMAGES OF ANY NATURE WHATSOEVER, DIRECTLY OR INDIRECTLY, ARISING FROM THE USE OF THIS SPECIFICATION. |
|
Table of Contents
1. Introduction
1.1 Background
1.2 Scope
1.3 Nomenclature
1.4 References
2. Meta-data
2.1 Overview
2.2 IEEE Meta-data Elements and Structure
2.3 Datatypes and Value Spaces of LOM Elements
2.3.1 Repertoire of ISO/IEC 10646-1:2000 Value Space
2.3.2 LanguageID Value Space
2.3.3 MIME Types Value Space
2.3.4 vCard Value Space
2.3.5 CharacterString Datatype
2.3.6 LangString Datatype
2.3.7 Vocabulary Datatype
2.3.8 DateTime Datatype
2.3.9 Duration Datatype
2.4 Data Model Changes from 1EdTech Learning Resource Meta-data v1.2.2
2.5 Conformance
2.5.1 Meta-data Instance Conformance
2.5.2 Application Profile Conformance
2.5.3 Smallest Permitted Maximum
2.6 Extensions
3. Taxonomies, Vocabularies, and the LOM
3.1 Rationale
3.2 Targeted Elements
3.3 Results
3.4 Conclusions and Recommendations
4. Implementation and Application Profiles
4.1 Planning
4.2 Application Profiles
4.2.1 General
4.2.2 Current Practice
4.2.3 Reference Implementations and Registries
4.2.4 Recommendations for Application Profiles
4.2.5 Vocabularies and Classification Schemata
4.2.6 Translations
4.2.7 Mapping Semantics
4.3 Implementation
4.3.1 Strict Implementation of the LOM Conceptual Data Schema
4.3.2 Extending the LOM Conceptual Data Schema
4.4 Exposing Meta-data
4.4.1 IEEE P1484.12.3 Standard for Extensible Markup Language (XML) Schema Definition Language Binding for Learning Object Metadata
4.4.2 Application Profile Bindings and Conformance
4.4.3 Migration from 1EdTech LRM XML Binding to the IEEE 1484.12.3 Standard for Extensible Markup Language (XML) Schema Definition Language Binding for Learning Object Metadata
4.4.4 Creating XML LOM Instances
Appendix A - Additional Resources
Appendix B - Mapping to Simple Dublin Core
Appendix C - 1EdTech LRM XML Binding IEEE LOM 1.0 XML Binding Transform
About This Document
List of Contributors
Revision History
Index
1. Introduction
The purpose of this document is to provide users and implementers of the 1EdTech Learning Resource Meta-data1 v1.3 Specification with a narrative description of the data model along with guidelines on its use, including the creation of application profiles. This Best Practice and Implementation Guide also provides a brief description of IEEE P1484.12.3 Standard for Extensible Markup Language (XML) Schema Definition Language Binding for Learning Object Metadata [LOMBind, 05] plus guidelines on binding meta-data instances. Designers and developers of online learning materials have an enormous variety of software tools at their disposal for creating learning resources. These tools range from simple presentation software packages to more complex authoring environments. They can be very useful in allowing developers the opportunity to create learning resources that might otherwise require extensive programming skills. Unfortunately, the wide variety of software tools available from a wide variety of vendors produce instructional materials that do not share a common mechanism for finding and using these resources.
Descriptive labels can be used to index learning resources making them easier to find and use. Such labels are "data about data" and when they are formally declared, or structured according to some specification, they are referred to as "meta-data". An example of meta-data is the label on a can of soup, which describes the can's ingredients, weight, cost, and so forth, usually in a small table with labels that are recognizable. Another example is a card in a library's card catalog, which describes a book, its author, subject, location within the library, and so forth.
A meta-data specification aims to make the process of finding and using a learning resource more efficient by providing a structure of defined elements that describe, or catalog, the learning resource and requirements about how the elements are to be used and represented.
1.1 Background
In 1997, the 1EdTech Project, initiated by the non-profit EDUCOM consortium (now EDUCAUSE) of US institutions of higher education and their vendor partners, established an effort to develop open market-based standards for online learning, including specifications for learning content meta-data.
Also in 1997, groups within the US National Institute for Standards and Technology (NIST) and the IEEE P.1484 study group (now the IEEE Learning Technology Standards Committee - LTSC) began similar efforts. The NIST effort merged with the 1EdTech effort and 1EdTech began collaborating with the ARIADNE Project, a European project with an active meta-data remit.
In 1998, 1EdTech and ARIADNE submitted a joint proposal and specification to the IEEE LTSC, which formed the basis of the IEEE LTSC Working Group 12 work on a draft standard for Learning Object Metadata (LOM). The standard developed by this working group is a multi-part standard: part one being a conceptual data schema (which corresponds to the 1EdTech Learning Resource Meta-data Information Model), parts two, three, and four being bindings of this schema in ISO/IEC11404, XML and RDF respectively.
As a result of significant worldwide interest, the 1EdTech Project was incorporated as the 1EdTech Consortium (1EdTech/GLC) in 1999, publicizing the IEEE work through its stakeholder community in the US, UK, Europe, Australia, and Singapore. This evolving stakeholder community has contributed feedback into the ongoing specification development process. In August 1999, 1EdTech/GLC released its Learning Resource Meta-data Specification v1.0 to the public, with minor revisions being released periodically up to v1.2.2 in November 2001. Each of these specification releases was based on updates of the IEEE LOM conceptual data schema with an accompanying XML Binding and Best Practice and Implementation Guide produced by 1EdTech/GLC.
On 12 June 2002, the conceptual data schema of the LOM was approved by the IEEE Standards Association as IEEE 1484.12.1 - 2002 Standard for Learning Object Metadata (IEEE LOM) [LOMInfo, 02], and the associated XML binding standard was approved as IEEE 1484.12.3 Standard for Extensible Markup Language (XML) Schema Definition Language Binding for LOM [LOMBind, 05] in 2005.
1EdTech Meta-data v1.2.2 specification was based on working draft 6.1 of the IEEE LOM standard. The IEEE standard finally published in June 2002 was based on working draft 6.4 of the LOM. With the release of this specification, 1EdTech Meta-data v1.3, the Information Model of the 1EdTech specification has been realigned with the published IEEE standard. The XML Binding of the 1EdTech Meta-data specification has also been realigned, given changes in the IEEE information model and to allow stricter checking of meta-data instances using an XML schema. Therefore, the 1EdTech Meta-data Specification v1.3 has been aligned to the IEEE 1484.12.1 and 1484.12.3 standards.
At the same time as changing its meta-data Information Model and XML Binding, 1EdTech/GLC is releasing this Best Practice and Implementation Guide and tools (in the form of an XSL transform) to assist developers and implementers who are using previous versions of the specification.
1.2 Scope
The IEEE LOM standard defines a set of meta-data elements that can be used to describe learning resources. This includes the element names, definitions, datatypes, and field lengths. The standard is known as a multi-part standard and defines both a conceptual model for the meta-data and an XML binding. The standard includes conformance statements for how meta-data documents must be organized and how applications must behave in order to be considered IEEE-conformant.
The 1EdTech Best Practice and Implementation Guide for the IEEE Standard for LOM therefore references:
- IEEE 1484.12.1 - 2002 Standard for Learning Object Metadata, which is used as the 1EdTech Learning Resource Meta-data Specification v1.3 Information Model [LOMInfo, 02]
- IEEE P1484.12.3 Standard for Extensible Markup Language (XML) Schema Definition Language Binding for Learning Object Metadata [LOMBind, 05]
This Best Practice and Implementation Guide for the 1484.12.1 - 2002 IEEE Standard for LOM provides general guidance about how an application may use LOM elements. The IEEE P1484.12.3 standard is accompanied by XML schemata to assist developers with their meta-data implementations. None of these IEEE or 1EdTech/GLC documents address details of meta-data implementation such as approaches to architectures, programming languages and data storage.
Use of the XSL transform is not covered in this document, separate guidance on its use is available from the 1EdTech Public Website at http://www.imsglobal.org/metadata/mdv1p3/imsmd_transformv1p0.html.
1.3 Nomenclature
1.4 References
| [Baker, 03] | DCMI Usage Board Review of Application Profiles, Dublin Core Metadata Initiative, 2003, http://dublincore.org/usage/documents/profiles/ |
| [Duval, 02] | Metadata Principles and Practicalities, Duval, E., Hodgins, W., Sutton, S. & Weibel, S. (2002), D-Lib Magazine, Vol 8 (4), http://www.dlib.org/dlib/april02/weibel/04weibel.html |
| [IAP, 05a] | 1EdTech Application Profile Guidelines: Part 1 - Management Overview V1.0, K.Riley & S.Wilson, 1EdTech/GLC, October 2005. |
| [IAP, 05b] | 1EdTech Application Profile Guidelines: Part 1 - Technical Manual V1.0, K.Riley & S.Wilson, 1EdTech/GLC, October 2005. |
| [IMSMD, 06b] | Guidelines for Using the 1EdTech LRM to IEEE LOM 1.0 Transform v1.0, C.Smythe, B.Towle, 1EdTech/GLC, August 2006. |
| [ISO5127, 01] | Information and Documentation - Vocabulary, ISO Standard, 2001 |
| [ISO/IEC10646-1, 00] | Universal Character Set, ISO Standard, 2000. |
| [ISO2788, 86] | Guidelines for the establishment and development of monolingual thesauri, ISO Standard, 1986. |
| [ISO3166-1, 97] | Codes for the Representation of Names of Countries, ISO Standard, 1997. |
| [ISO639, 88] | Code for the representation of the names of languages, ISO Standard, 1988. |
| [ISO8601, 00] | Data elements and interchange formats - Information interchange - Representation of dates and times, L.Visser, ISO Standard, 2000. |
| [LOMBind, 05] | 1484.12.3-2005 IEEE Standard for Extensible Markup Language (XML) Schema Definition Language Binding for Learning Object Metadata, The Institute of Electrical and Electronics Engineers, Inc., 2005. |
| [LOMInfo, 02] | 1484.12.1-2002 IEEE Standard for Learning Object Metadata, The Institute of Electrical and Electronics Engineers, Inc., 2002. ISBN:0-7381-3297-7. |
| [Ottawa, 01] | The Ottawa Communique http://www.ischool.washington.edu/sasutton/dc-ed/Ottawa-Communique.rtf, Ottawa, 2001. |
| [RFC1766, 95] | Tags for the Identification of Languages, H.Alvestrand, Internet Engineering Task Force, 1995, http://www.ietf.org/rfc/rfc1766.txt |
| [RFC2048, 96] | Multipurpose Internet Mail Extensions (MIME) Part Four: Registration Procedures, N.Freed, J.Klensin and J.Postel, Internet Engineering Task Force, 1996, http://www.ietf.org/rfc/rfc2048.txt |
| [RFC2425, 98] | A MIME Content-type for Directory Information, T.Howes, M.Smith and F.Dawson Internet Engineering Task Force, 1998, http://www.ietf.org/rfc/rfc2425.txt |
| [RFC2426, 98] | vCard MME Directory Profile, F.Dawsob and T.Howes, Internet Engineering Task Force, 1998, http://www.ietf.org/rfc/rfc2426 |
| [VDEX, 04a] | 1EdTech Vocabulary Definition Exchange (VDEX) Information Model Specification Final Release v1.0, A.Cooper, 1EdTech/GLC, February, 2004. |
| [VDEX, 04b] | 1EdTech Vocabulary Definition Exchange (VDEX) Best Practice & Implementation Guide Final Release v1.0, A.Cooper, 1EdTech/GLC, February, 2004. |
2. Meta-data
2.1 Overview
The IEEE conceptual data schema for meta-data definitions is hierarchical. At the base of the hierarchy is the "root" element. The root element contains many sub-elements. If a sub-element itself contains additional sub-elements it is called a "branch". Sub-elements that do not contain any sub-elements are called "leaves". This entire hierarchical model is called the "tree structure" of a document. The relationship between the root, branches, and leaves is depicted in Figure 2.1 using sample elements from the IEEE LOM standard.
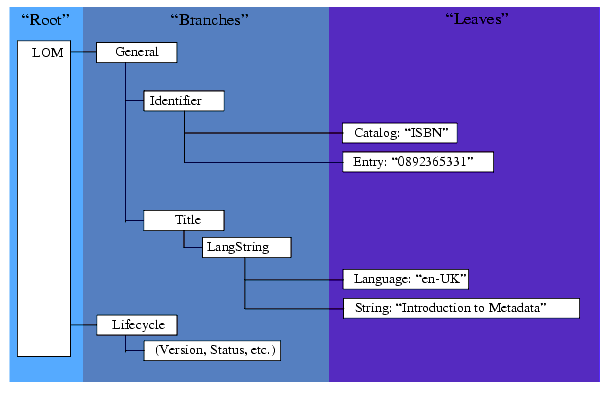
Each element in the meta-data hierarchy has a specific definition, datatype, and value space. Complete details about each meta-data element can be found in the conceptual data schema for IEEE 1484.12.1 - 2002 Standard for LOM. Further information about the activities of the IEEE LOM Working Group is available at http://ltsc.ieee.org/wg12/index.html.
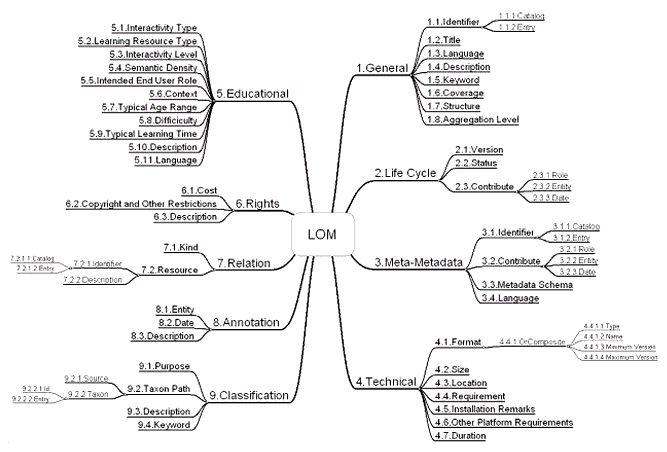
2.2 IEEE Meta-data Elements and Structure
The IEEE LOM standard conceptual data schema lists all the meta-data elements in tabular format. To complement this table, Figure 2.2 presents a graphical illustration of the elements in the data schema, which shows how the elements are divided into nine top level categories: General, Life Cycle, Meta-Metadata, Technical, Educational, Rights, Relation, Annotation, and Classification. Each of these branches comprises several elements, some of which are leaves, others are sub-branches which lead to leaves. Not shown in Figure 2.2 are the leaf elements associated with the element types such as "LangString", "Vocabulary", "DateTime" and "Duration", which are described below in sub-section 2.3. The reader is referred to the IEEE LOM conceptual data schema for a full account of the types and value spaces of each element.
2.3 Datatypes and Value Spaces of LOM Elements
Each leaf element in the LOM conceptual data schema has a datatype and a value space that defines the encoding of the data for that element. These datatypes and value spaces sometimes restrict how an element may be used, for example by specifying a restricted vocabulary, and may also provide the facility to encode extra information, such as multilingual entries. Value spaces that are LOM vocabularies are not listed here; they are described in the IEEE LOM conceptual data schema and are discussed in Section 3 of this guide.
2.3.1 Repertoire of ISO/IEC 10646-1:2000 Value Space
ISO/IEC 10646-1:2000 is also known as Unicode 3.0.1 [ISO/IEC10646-1, 00]. This value space allows the use of an extensive list of international letters, glyphs, and other characters.
2.3.2 LanguageID Value Space
Values for LanguageID take the form Langcode(-Subcode) where the value space for Langcode is defined by ISO 639:1988, which specifies two and three letter codes for languages and the value space for Subcode is defined by ISO 3166-1:1997 [ISO3166-1, 97], which specifies two letter codes for countries. This allows for regional variations to be recorded where they are significant, for example UK, Australian, and US English can be distinguished as en-UK, en-AU, and en-US respectively. The schema states that this approach is in accordance with (IETF) RFC 1766 [RFC1766, 95], which specifies that where a two letter language code is available it should be used in preference to the three letter code. This RFC also allows the use of the codes x- and i- in place of ISO 639 [ISO639, 88] language codes for extensions. The value i- is reserved for extensions that have been registered with IANA, the value x- allows unregistered private extensions. A point of divergence between RFC 1766 and the LOM LanguageID value space is that "none" is an acceptable value in LOM usage.
2.3.3 MIME Types Value Space
MIME types allow the encoding of the digital format of a resource. A full listing of registered types can be found at http://www.iana.org/assignments/media-types/ and procedures for creating and registering new types are described in [RFC2048, 96].
2.3.4 vCard Value Space
IMC vCard is a structured text string that encodes information similar to that found on a business card. The technical details are given in [RFC2425, 98] and [RFC2426, 98] and a more general overview is available at http://www.imc.org/pdi/.
2.3.5 CharacterString Datatype
This is the most basic LOM datatype, being a string of characters conforming to the value space of the relevant element.
2.3.6 LangString Datatype
The LangString datatype allows multiple semantically equivalent entries of the information about the characteristic described by the LOM element. Each entry is in two parts: String and Language. String contains the information describing the characteristic, and Language specifies the language in which this is recorded. This allows the same information to be given in several languages in a single LOM element. For example, even though a LOM record can have only one instance of 1.2 General.Title, this instance is a LangString allowing the title to be given in other relevant languages. Where the Strings are semantically different, multiple instances of the LOM element should be used (for example, when providing several alternative keywords in English for element 1.5 General.Keyword).
2.3.7 Vocabulary Datatype
Many LOM elements take their entry from a value space which is a limited choice of words or phrases, i.e. a restricted vocabulary. For most of these elements, the LOM conceptual data schema provides a default vocabulary. For all such elements the entry is encoded as a Vocabulary datatype, which comprises two parts: the Source of the restricted vocabulary and the Value. Where the default vocabulary is used, the Source would be "LOMv1.0" but other vocabularies could be used, in which case they should be identified by a similar abbreviation or by a URI.
2.3.8 DateTime Datatype
The DateTime datatype allows a point in time to be encoded numerically or described textually. There are two parts to each element of this datatype: the DateTime and a Description. The DateTime allows the date and time of day to be specified according to [ISO8601, 00], for example 2003-07 (July 2003). The Description part is useful for dates which cannot be specified in this way, for example "late June 1966" or "about 2 million years BC". The description is given as a LangString (see above).
2.3.9 Duration Datatype
The duration datatype allows periods of time to be encoded numerically or described textually. There are two parts to each element of this type: the Duration and a Description. The Duration provides the length of the period according to [ISO8601, 00], for example P3M for three months, P3m58s for three minutes 58 seconds. A description of the Duration can be provided for periods that are not well described by this scheme, for example "about half an hour". The description is given as a LangString (see above).
2.4 Data Model Changes from 1EdTech Learning Resource Meta-data v1.2.2
This section summarizes the differences between the 1EdTech Learning Resource Meta-data Information Model v1.2.2 and the IEEE LOM conceptual data schema, which forms the Information Model for 1EdTech Meta-data v1.3.
The changes from the IEEE LOM draft v6.1 to the final standard can be found in IEEE 1484.12.1 Standard for LOM Summary of Changes document which can be found at http://ltsc.ieee.org/wg12/files/LOMChangesSummary_2.pdf. Since 1EdTech Learning Resource Meta-data v1.2.2 was based on the IEEE LOM draft v6.1, this Summary of Changes serves as an account of the differences between Learning Resource Meta-data v1.2.2 and v1.3, with two classes of exception:
- 1EdTech Learning Resource Meta-data v1.2.2 was based on draft v6.1 of the IEEE LOM, however some small changes were made in this process (these were the renaming of LOM element names "keywords" and "requirements" to "keyword" and "requirement" in 1EdTech Learning Resource Meta-data v1.2.2). These changes were incorporated into the final version of the IEEE LOM. Thus, while these are listed in the IEEE Summary of Changes, they are not points of difference between 1EdTech Learning Resource Meta-data v1.2.2 and v.1.3.
- There are differences between 1EdTech Learning Resource Meta-data Information Model v1.2.2 and the IEEE LOM standard that are not accounted for in the IEEE Summary of Changes. These are:
- The vocabulary type in 1EdTech Meta-data comprised source and value elements that were LangStrings. In the LOM version 1.0 they became CharacterStrings.
- Some other LangStrings became CharacterStrings, namely the entry part of an 1EdTech CatalogEntry / LOM identifier (elements 1EdTech 1.3.1 / LOM 1.1.2 and 1EdTech 3.2.2 / LOM 3.1.2, 1EdTech 7.2.3.1 / LOM 7.2.1.2).
- The Educational category changed from being a single instance to having a smallest permitted maximum of 100.
XSLTs has been written and are publicly available at: http://www.imsglobal.org/metadata/. These XSLTs provide information on transforming from various versions of 1EdTech LRM to IEEE LOM 1.0. For more information, see Appendix C.
2.5 Conformance
The conceptual data schema of IEEE 1484.12.1 - 2002 Standard for LOM defines levels of conformance for meta-data instances. A definition of instance conformance is provided below which is the same as that provided for 1EdTech LRM v1.2.2.
2.5.1 Meta-data Instance Conformance
The IEEE LOM defines instance conformance as follows:
2.5.2 Application Profile Conformance
For further guidelines regarding application profile conformance see Section 4.4.2 Application Profile Bindings and Conformance and the 1EdTech Application Profile Guidelines document [IAP, 05a].
2.5.3 Smallest Permitted Maximum
The smallest permitted maximum is the smallest number of occurrences of an element that an application must be able to handle or manage. This means that for meta-data instances the smallest permitted maximum is the maximum number of occurrences of an element that can be guaranteed to pass from one system to another. For example, the smallest permitted maximum for the Annotation category is 30 items, however a meta-data instance may contain 40 occurrences of the Annotation category. A conforming LOM application receiving this instance may import only 30 of these occurrences. It is therefore important that the originator of the meta-data instance is aware that ten occurrences of the annotation may not be displayed by all systems. Since the Annotation category is unordered there is no way of knowing which occurrences will not be represented. Other LOM elements are ordered (for example 5.2 Education.Learning Resource Type) with the most dominant values being recorded first, in such instances the less dominant values that exceed the smallest permitted maximum may not be represented.
2.6 Extensions
The IEEE LOM conceptual data schema is designed in such a way as to facilitate extensions to the schema. Such extensions may take the form of new terms for existing vocabularies, new vocabularies for existing elements, or new elements. Extensions to the LOM must retain the data types and must not delete values from the value spaces of existing LOM v1.0 base schema data elements. New values may be added to an existing LOM v1.0 value space but must be identified as coming from a source other than LOM v1.0 when they are used in an instance. As vocabularies can act as qualifiers for elements, vocabulary extensions should be chosen to provide semantic consistency with the LOM conceptual data schema element with which they are used. Guidelines on how to extend the LOM are provided in sub-section 4.3.2 and sub-section 4.4.2.
3. Taxonomies, Vocabularies, and the LOM
Taxonomies and vocabularies are structured collections of terms that can serve as values for meta-data elements. They are part of the IEEE LOM conceptual data schema and are subject to best practice policies. This section outlines current 1EdTech best practice for taxonomies and vocabularies.
Just as meta-data elements must accurately describe resources, the taxonomies and vocabularies that are their corresponding values also need to be precise. In addition, the taxonomies must be familiar both to developers and consumers of learning resources. Useful and usable meta-data elements and taxonomies help to facilitate interoperability and the sharing of learning resources. Hence, best practice considerations are as relevant to taxonomies and vocabularies as to other aspects of the LOM.
It is recognized that no single controlled vocabulary will be acceptable to all communities, however it is best practice to use widely accepted vocabularies in preference to home grown schemes in order to facilitate interoperability. The following factors should be considered when selecting an appropriate vocabulary:
- Authority;
- Stability;
- Maintenance;
- Currency;
- Coverage;
- Multilinguality;
- Extent of current use;
- Applicability to user communities' requirements;
- Conformance to standards and specifications, e.g., ISO 2788 [ISO2788, 86] and 1EdTech Vocabulary Definition Exchange specification [VDEX, 04a].
Taxonomies and vocabularies are structured collections of terms that can serve as values for the meta-data elements discussed previously. They are part of the IEEE/1EdTech set of meta-data and are subject to best-practice policies. This Section outlines current 1EdTech best-practice guidelines for taxonomies and vocabularies.
3.1 Rationale
Just as meta-data elements must accurately describe resources, the taxonomies and vocabularies that are their values also need to be precise. Just as meta-data elements must be easy to identify and use, taxonomies must be familiar both to developers and consumers of learning resources. Useful and usable meta-data elements and taxonomies together provide the foundation for a vigorous market in learning resources. Hence, best-practice considerations apply to taxonomies and vocabularies as forcefully as to other aspects of 1EdTech Meta-data.
Viewed from this perspective, the goal of 1EdTech Meta-data best practices as applied to taxonomies and vocabularies is to work with various communities interested in learning resources - including developers, catalogers and consumers - to foster the adoption of taxonomy standards that are shared as widely as possible. 1EdTech wants to make the communities aware of standardized (or at least popular and useful) taxonomies that might suit their needs; and to try to minimize the creation of new "home-grown" taxonomies by communities, when existing ones are perfectly adequate for their purposes.
Best practices guidelines concerning taxonomies and vocabularies do not require or even recommend a single taxonomy. As we learned from our earlier 1EdTech taxonomies work, no single controlled vocabulary such as, say, the Library of Congress Subject Headings (whose elements might be values for the discipline characteristic of classification.purpose) will be acceptable to all communities. Rather, the guidelines are based on a broad survey of various fields of use and of several 1EdTech Meta-data properties or elements that take taxonomies as values. The guidelines will provide information about the many vocabularies that are "best" - or at least commonly used - to describe learning resources in these communities and for these meta-data properties.
3.2 Targeted Elements
The initial set of elements was selected simply by looking at all properties in the IEEE LOM Draft Standard that take vocabularies or taxonomies as values. The criteria used to select important elements included whether the element was well-defined, understood by communities of users and also had emerging standard taxonomies associated with them (the "low hanging fruit" was generally viewed as more important).
This initial list of elements was extended through discussions with key contacts in the different fields of use. In particular, several of these groups were already developing and using vocabularies for additional 1EdTech Meta-data properties (often ones that on our estimate appeared formative or even ill-defined). These have been included in cases where the controlled vocabularies appear to be relatively broadly used within a significant community or practice. and even though, in some cases, the vocabularies may not yet be stable. This means that some of the included vocabularies and taxonomies were ones that were popular in one field of use, but not necessarily in others; further, some whole elements or properties seem to be important in one field, but are rarely used in others, if at all.
| Element1 | Description2 |
|---|---|
| general.language | The human language used by the typical intended user of the resource. |
| classification.purpose [discipline] | Subject area (note: general.keywords may also be used to record subject information). |
| technical.format | Technical data type of the resource. |
| educational.learningcontext | Typical kind of learners; grade or competence level usually associated with a resource (note classification.purpose [Educational Level] may also be used to record level or grade-related information). |
| technical.requirement.Name | Operating system(s) under which resource can run (only if Type='Operating System'). |
| general.aggregationlevel | The functional size of the resource. |
| classification.purpose [Educational Objectives] | Learning goal. |
| educational.learningresourcetype | Specific kind of resource, most dominant kind first. |
| educational.interactivitytype | The type of interactivity supported by the resource. |
| educational. interactivitylevel | Level of interactivity between an end user and the resource. |
| educational.intendedenduserrole | Normal user of the resource, most dominant first. |
| educational.difficulty | How hard it is to work through the resource for the typical target audience. |
| educational.typicallearningtime | Approximate or typical time it takes to work with the resource. |
|
1In some cases the elements listed here are not ones that have values; rather values are associated with subelements. For example, values are associated with educational.typicallearningtime.datetime, not, strictly speaking, with educational.typicallearningtime. For simplicity, we use the ellipsis where it creates no ambiguity.
2In most, but not all cases, these descriptions are taken from the 1EdTech Meta-data specification.
|
3.3 Results
Discussions with key contacts in the various fields of use have enabled us to find several dozen vocabularies and taxonomies for targeted meta-data. The vocabularies differ across many dimensions. They range from small vocabulary lists, such as two options for metametadata.contribute.role (Creator, Validator), to multi-level discipline taxonomies comprising hundreds of terms. In many cases, such as classification.purpose [discipline], vocabularies are long-established; in others they are of relatively recent (home-grown) origin, and often used only by that field, or perhaps even a small community within a sector. For some elements (discipline again is an example), there are several competing taxonomies, even within a single field of use. For other elements, no dominant vocabulary has emerged for any field. The following paragraphs present our survey results in some detail, and summarize some best-practice guidelines.
3.4 Conclusions and Recommendations
The following table summarizes the results of our survey of taxonomies and vocabularies, listing formal and informal designations for schemes that were nominated for the elements discussed above by various fields of use. The table also points to sources (URLs for locations that list the vocabularies in complete detail, and in some cases that represent a controlling authority which maintains this information). Finally, the table also notes some summary characteristics for each taxonomy or vocabulary, limited mainly to comments on overall structure, origins, relationships to other vocabularies, stability and maturity, and whether the vocabulary is open or controlled.
For a couple of reasons not all of these vocabularies can be viewed as "best practices" in any strict sense, nor even highly recommended choices for their associated meta-data element. First, in some cases, such as discipline, several very mature alternative taxonomies are popular -- even within a single field of use. No single one emerges as best, except, perhaps, in very specialized fields, such as medicine. Second, many of the vocabularies are relatively unstable and immature. For these reasons, the taxonomies summarized below are, in general, best viewed as common practice guidelines, rather than best practice recommendations. In most cases, prospective users of taxonomies -- whether using them to describe known resources or to construct searches for unknown ones -- should consider their needs, the appropriate topic area and field, as well as the credibility of sources of alternative vocabularies, as part of the process of deciding what practice is best for them.
The table of common practice taxonomies also suggests features of several taxonomy services that could help users learn about available vocabulary alternatives and select ones appropriate to their meta-data needs. Perhaps the most important insight is that to choose the right vocabularies - ones in particular that are shared by wide communities of practice - users will need more than simple access to registries or repositories that catalog taxonomies and vocabularies. In addition, they will need access to information that can quickly educate them about the features of the various vocabulary alternatives available to them. The kinds of information that have surfaced during this survey and analysis include:
- element name;
- field of use;
- source location;
- maintaining agency;
- extensibility policies;
- user community or audience;
- stability;
- completeness (and related quality judgements);
- relationships (with other taxonomies and vocabularies).
Pieces of information appearing first are just basic identification; others identify the source and communities of practice; the final ones are (sometimes subjective) assessments of the maturity of the vocabulary, relative to its user community. This list is not complete. A full- functional collection of taxonomy services built along these lines would not only allow users to choose the most appropriate vocabularies, but would also help extend the terms, as needed, in coordination with the maintaining authorities.
| Element | Taxonomy / Vocabulary Schema | Fields of Use | Characteristics | Sources |
|---|---|---|---|---|
| general.language | RFC 1766 | US Higher Ed AU Higher Ed |
Stable and mature; national/international scope; controlled vocabulary | http://www.imc.org/rfc1766 |
| ABS 1267 | AU Higher Ed, AU K12 |
Relatively stable and mature; national scope; controlled vocabulary | ||
| ISO639; ISO3166 | AU Higher Ed, US Higher Ed |
Stable and mature; national/international scope; controlled vocabulary | http://www.iso.ch/ | |
| Z39.53 | US Higher Ed | Stable and mature; national/international scope; controlled vocabulary | http://www.oasis-open.org/cover/nisoLang3-1994.html | |
| classification. purpose [discipline] (also general.keywords, applied to subjects) |
LCC (Library of Congress Classification) | US Higher Ed | Stable and mature; national/international scope; controlled vocabulary | http://lcweb.loc.gov |
| LCSH (Library of Congress Subject Headings) | US Higher Ed | Stable and mature; national/international scope; controlled vocabulary | http://lcweb.loc.gov | |
| DDC (Dewey Decimal Classification) | US Higher Ed | Stable and mature; national/international scope; controlled vocabulary | http://www.oclc.org/oclc/fp/ | |
| UDC (Universal Decimal Classification) | EU Higher Ed | Stable and mature; national/international scope; controlled vocabulary | http://zeus.slais.ucl.ac.uk/udc/ | |
| CIP (Classification of Instructional Programs) | US Higher Ed US Workforce Training |
Stable and mature; national scope; controlled vocabulary | http://nces.ed.gov/ | |
| DDC (top level with selective deepening) | US Higher Ed | Relatively unstable and immature; home-grown (variant of DDC with a terms from second- and third-levels added to first-level of DDC taxonomy) | http://merlot.org/home/SubjectCatIndex.po | |
| Doleta Subject Headings | US Workforce Training | Somewhat stable and mature; national scope; controlled vocabulary | http://www.fed-training.org/workspace/Flx-data/flx-provider.htm | |
| LRE Thesaurus | European K12 Ed | Stable and mature vocabulary | http://insight.eun.org/ww/en/pub/insight/interoperability/learning_resource_exchange/metadata.htm | |
| GEM subject taxonomy | US K12 | Relatively stable and mature; home-grown (began as DDC variant); controlled vocabulary | http://www.geminfo.org/Workbench/Metadata/Vocab_Subject.html | |
| SCIS Subject Headings | AU K12 | Stable and mature; national scope; controlled vocabulary | http://www.curriculum.edu.au/scis | |
| Singapore HE Subject taxonomy | Asia Higher Ed | New vocabulary, evolving; national scope; home-grown; controlled vocabulary | ?? | |
| Singapore K12 Subject taxonomy | Asia K12 Ed | New vocabulary, evolving; national scope; home-grown; controlled vocabulary | ?? | |
| general. aggregation level |
DoD cross-services harmonization | US Military Training | New and immature vocabulary; home-grown harmonization of vocabularies from different services | http://www.rhassociates.com/ADL-TWG/SCORM(0.7.3).doc |
| Singapore granularity list | Asia Higher Ed | New vocabulary, evolving; national scope; home-grown; controlled vocabulary | ?? | |
| technical. format |
RFC 1521 | AU Higher Ed, US Military Training |
Relatively stable and mature; national/international scope; controlled vocabulary | http://www.isi.edu/in-notes/iana/assignments/media-types/media-types |
| GEM format controlled vocabulary | US K12 | Relatively stable and mature; home-grown (Subset of RFC 1521 media types); controlled vocabulary | http://www.geminfo.org/Workbench/Metadata/Vocab_Format.html | |
| Merlot format list | New vocabulary, mature; home-grown; restricted vocabulary | http://merlot.org/search/AdvArtifactSearch.po | ||
| educational. learningcontext (also classification. purpose [Educational Level] |
DoL default level | Uncertain stability and maturity; home-grown; restricted vocabulary | http://www.alx.org/alxoffer.html | |
| Edna.UserLevel | AU Higher Ed, AU K12 |
Somewhat stable and mature; home-grown; restricted vocabulary | http://www.edna.edu.au/EdNA/genericpage.html?file=/edna/aboutedna/metadata/schemes.html&sp=eec099eeeeeb#EDNA.Userlevel | |
| Singapore use level list | AU Higher Ed | New vocabulary, evolving; national scope; home-grown; controlled vocabulary | ||
| Gem grade controlled vocabulary | US K12, US Higher Ed |
Relatively stable and mature; home-grown; controlled vocabulary | http://www.geminfo.org/Workbench/Metadata/Vocab_Grade.html | |
| Merlot Primary Audience | US Higher Ed, US K12 Education |
New vocabulary, evolving; home-grown; restricted vocabulary | http://merlot.org/search/AdvArtifactSearch.po | |
| educational. learning resourcetype |
1EdTech default | US Military Training | New vocabulary, evolving; home-grown; open vocabulary | http://www.rhassociates.com/ADL-TWG/SCORM(0.7.3).doc |
| DC.Type "current thinking" | US Higher Ed | Relatively unstable and immature; home-grown; open vocabulary | http://www.agcrc.csiro.au/projects/3018CO/metadata/dc_tf/type_simple.html or http://purl.org/dc/documents/working_drafts/wd-typelist.htm |
|
| GEM resource-type controlled vocabulary | US K12 | Somewhat stable and mature; home-grown (Extension of DC recommended list); controlled vocabulary | http://www.geminfo.org/Workbench/Metadata/Vocab_Type.html | |
| Edna.Type | AU Higher Ed AU K12 |
Relatively unstable and immature; home-grown (based on DC.Type recommendation); controlled vocabulary | http://www.edna.edu.au/EdNA/genericpage.html?file=/edna/aboutedna/metadata/schemes.html&sp=eec099eeeeeb#EDNA.Type | |
| Singapore resource type list | Asia Higher Ed | New vocabulary, evolving; national scope; home-grown; controlled vocabulary | ?? | |
| Merlot form "Item Type" list | US Higher Ed | New vocabulary, evolving; home-grown; restricted vocabulary | http://merlot.org/search/AdvArtifactSearch.po | |
| educational. interactivitytype |
Singapore pedagogical approach list | Asia Higher Ed | New vocabulary, evolving; national scope; home-grown; controlled vocabulary | ?? |
| GEM pedagogy controlled vocabulary | US K12 | Somewhat stable and mature; home-grown; controlled vocabulary | http://www.geminfo.org/Workbench/Metadata/Vocab_Pedagogy.html | |
| educational. interactivitylevel |
Singapore interactivity list | Asia Higher Ed | New vocabulary, evolving; national scope; home-grown; controlled vocabulary | ?? |
| educational. intended enduserrole |
Singapore user role list | Asia Higher Ed | New vocabulary, evolving; national scope; home-grown; controlled vocabulary | ?? |
| GEM Audience controlled vocabulary | US Higher Ed | Somewhat stable and mature; home-grown; controlled vocabulary | http://www.geminfo.org/Workbench/Metadata/Vocab_Audience.html | |
| educational. difficulty |
Singapore difficulty list | Asia Higher Ed | New vocabulary, evolving; national scope; home-grown; controlled vocabulary | ?? |
For further guidance on using taxonomies and vocabularies with the LOM see the CEN/ISSS Learning Technologies Workshop draft CEN Workshop Agreement Controlled Vocabularies for Learning Object Metadata at
http://www.cenorm.be/cenorm/businessdomains/businessdomains/informationsocietystandardizationsystem/elearning/learning+technologies+workshop/learning+technologies+workshop.asp.
4. Implementation and Application Profiles
4.1 Planning
One of the first steps in planning a meta-data implementation is to identify all the meta-data elements the implementation will need to support. This can be done in several ways. One approach is to imagine how to label the learning resources that the implementation will describe. What kind of information should the resources carry with them? It may be useful to try this exercise without first looking through the IEEE LOM standard conceptual data schema. An alternative approach is to go through the LOM conceptual data schema checking off each element that will be required to serve the needs of the implementation. It is important to keep end users in mind when listing these meta-data elements. Implementers should evaluate whether an element is critical to the implementation or whether it is just "nice to have". Meta-data elements are similar to features of a modern software application. Just as software engineers must be wary of "feature creep", so should meta-data implementers be wary of "meta-data creep". In a worst case scenario, the requirement may be for a convenient means of easily describing online learning materials but the application may demand considerable resources in terms of time and cataloguing expertise.
4.2 Application Profiles2
4.2.1 General
For education and training stakeholders the standardization during 2002-2003 of the two international meta-data standards (IEEE LOM and Dublin Core) represents a significant milestone. Officially known as IEEE 1484.12.1-2002 Standard for Learning Object Metadata (LOM), and ISO 15836 (the Dublin Core Metadata Element Set) these data models provide important reference points for implementers building and managing systems that support e-learning.
In practice, organizations and communities will find it necessary to implement the LOM in ways that meet their specific requirements. To do this, they create "application profiles", a term that has been adopted by the broader meta-data community to describe meta-data element sets that are either abbreviated versions of complete standards or are a heterogeneous mix of elements drawn from different meta-data schemata. Typically, application profiles are developed to meet the needs of a specific application, within a specific community. For example, to exchange meta-data records among higher education institutions within a country; to ensure that content coming to a government agency from a variety of external sources can be incorporated into the catalog supported by the agencies learning management system; or, to support the distributed development of learning resource material by learning teams within a corporation. However, there is currently diverse practice relating to the definition and implementation of application profiles. While the development of application profiles provides the opportunity for implementer communities to meet their local needs, balancing interoperability with local requirements can be a significant challenge.
To facilitate interoperability, the LOM standard specifies ways in which application profiles can be created. As a further aid, this Best Practice and Implementation Guide includes additional guidelines that represent current thinking. Additional references are provided below.
4.2.2 Current Practice
The 1EdTech Meta-data Special Interest Group recognizes that the 1EdTech community implements a variety of meta-data specifications and standards. Two approaches to the development of application profiles are currently emerging. One involves combining elements from different meta-data schemata and the other constrains and extends a single schema. As an example of the first approach, the DCMI community defines its position as follows:
As an example of the first approach, the DCMI community defines its position as follows:
Typically, however, a number of communities have interpreted application profiles as a means to also incorporate their own specific local requirements and terminology. For example, the SCHEMAS Registry provides examples of such usage and defines an application profile in the following simple terms: "an application profile selects elements from one or more namespace schemas." (SCHEMAS)
As an example of the second approach the Coalition for Networked Information, defines profiles as "customizations of the standard to particular communities of implementers with common applications requirements". This second approach focuses on a single meta-data standard and its elements. The LOM for example, is typically implemented by creating application profiles that restrict the elements used, designate certain elements as mandatory or optional, specify vocabulary usage and interpretation, and add organization or community specific classification schemes. Implementers may also constrain the data model by dictating the way in which elements are used and repeated. Examples include the UK LOM Core, SingCore, and the SCORM2004 Profile of LOM.
A pragmatic approach has been developed through the collaborative efforts of IEEE LTSC and DCMI, whose position on application profiles was articulated as a result of the Ottawa Communique [Ottawa, 01]. A jointly authored paper, Metadata Principles and Practicalities [Duval, 02] was released following the Ottawa Communique. This paper defines application profiles in the following terms:
4.2.3 Reference Implementations and Registries
With the proliferation of meta-data application profiles also comes the need for registries. A number of important registries for meta-data schemata and associated vocabularies have already been implemented. These include:
- SCHEMAS:
http://www.schemas-forum.org/registry/desire/appprofile.php3 - CORES:
http://www.cores-eu.net/registry/schema - CEN/ISSS Vocabularies Registry:
http://www.cenorm.be/cenorm/businessdomains/businessdomains/informationsocietystandardizationsystem/elearning/learning+technologies+workshop/vocrep.htm
Like namespaces, registries provide an authoritative role in facilitating data sharing and interchange. Registries also provide a forum for schema validation and comparative analysis, informing stakeholders of rules and protocols associated with data sharing. Registries can reference a diverse array of information including entire standards or specifications, their components, bindings, data elements, vocabularies, reference implementations, guidelines and best practices. From an interoperability perspective, registries are useful because they provide a common method for representing the characteristics of the items (schemata, application profiles, vocabularies, etc.) that are registered.
1EdTech recommends that implementers adopting the application profile approach to meta-data schema development should consider the role that registries play and register their profiles accordingly. Example application profiles are listed in Appendix A.
4.2.4 Recommendations for Application Profiles
To successfully create an application profile it is necessary to:
- Understand the requirements and clearly define the purpose(s) of the profile;
- Ensure that adequate resources are available for the process of creating and maintaining the profile;
- Review existing relevant standards, specifications, and application profiles (check meta-data registries for current schemata). If an application profile is found that meets the implementer's community requirements, it should be used as is or if necessary modified to meet these requirements;
- Distinguish among profiles used for storing meta-data for internal use, for exposing meta-data for search and discovery, and for exchanging meta-data records with other systems;
- Determine what other applications with which the profile needs to interoperate;
- Follow the recommendations below regarding:-
- Publish the application profile(s) in a meta-data schema registry
For further information concerning application profiles, please refer to the 1EdTech Application Profile Guidelines [IAP, 05a] documents found on the 1EdTech Website at: http://www.imsglobal.org/ap/index.html
4.2.5 Vocabularies and Classification Schemata
ISO defines a vocabulary as "a dictionary of terms related to a particular subject field" [ISO 5127/2-1983].
The LOM conceptual data schema uses different kinds of vocabularies that serve different needs. The following types of vocabularies may be used to qualify LOM elements:
- Simple vocabularies and value lists;
- Classifications and taxonomies;
- Thesauri;
- Glossaries, dictionaries, and ontologies.
For further discussion regarding Taxonomies, Vocabularies, and the LOM, refer to sub-section 3 above.
Only simple vocabularies and value lists are typically used in relation to the LOM vocabulary datatype. The vocabulary datatype is a combination of two parts: the first identifies the source of the vocabulary or list of values, the second identifies the values of the vocabulary or list. Vocabulary values are typically terms, short strings, or integers. The source of the vocabulary is generally a namespace, URI, or URL. Ideally, this source namespace, URI or URL should provide a list of acceptable values and their definitions. Elements that are subject to the vocabulary datatype should cite openly referenced and maintained value sets.
Particular communities may find LOM based vocabularies insufficient and may achieve increased specificity in describing their learning resources by using terms that have high semantic value within that community. However implementers should be aware that this approach compromises interoperability when records created using different application profiles are exchanged. Consequently, it is advisable that local or customized vocabularies should be used in conjunction with the vocabularies recommended by the LOM conceptual data schema. (Note: this technique is based on the LOM recommendations for 5.6:Educational.Context: "Suggested good practice is to use one of the values of the value space and to use an additional instance of this data element for further refinement.")
- Use one of the vocabulary values recommended by the LOM. If no clearly suitable value is available, use the LOM value that, by virtue of its generality, connotative meanings or other attributes, is closest in meaning and most accurate;
- Repeat the metadata element and provide both the source location and appropriate value(s) for the locally developed or custom controlled vocabulary. Where this technique is not possible, e.g., only one instance of the element is permitted, implementers are encourage to use the LOM vocabulary; however, the use of alternative vocabularies may sometimes be unavoidable.
If it is necessary to create new vocabulary terms, they should be chosen from a recognized source, or where no appropriate terms or vocabularies exist, new terms may be created and a source identified (see 1EdTech Vocabulary Definition Exchange Best Practice and Implementation Guide Specification Section 2 [VDEX, 04b]). For further guidelines for selecting appropriate vocabularies see sub-section 3 of this document above. When using a term from a vocabulary other than those declared in the LOM, the specific vocabulary being used must be identified in the source element of the vocabulary item, suggested best practice is to use identifiers that are likely to be unique over their expected lifetime, preferably URIs based on registered names. For example, if the vocabulary for 5.2 Educational.Learning Resource Type has been supplemented with the term "MotivatingExample" from a hypothetical vocabulary (URI http://www.vocabularies.org/LearningResourceType) then a fragment of a LOM instance might look like this:
<context>
<source>LOMv1.0</source>
<value>narrative text</value>
</context>
<context>
<source>http://www.vocabularies.org/LearningResourceType</source>
<value>MotivatingExample</value>
</context>
If the element is not repeatable, implementers may choose to use their own customized vocabulary but should be aware that customized vocabularies may not be recognized by other conforming applications.
4.2.6 Translations
There are a number of considerations that are important to bear in mind when implementing the LOM in non-English or multilingual contexts:
The CEN/ISSS WS-LT (Work Shop on Learning Technologies; http://www.cenorm.be/isss/Workshop/lt/) has undertaken translation of the LOM conceptual data schema (element titles and vocabulary values) into a variety of European languages. At the time of writing, most of these translations have not been made publicly available in finalized form.
In the context of XML bindings for the LOM, LOM element names and vocabulary values should not be translated. In an XML schema document or XML-formatted record, the original English versions of these names and values should be regarded as linguistically neutral strings or tokens. Equivalents in alternative languages should be provided through the user interface or any other mechanisms through which these element titles and vocabulary values are presented to end-users. The failure of applications to present different labels in their user interfaces from those stored in the actual XML files is a considerable inconvenience for those that cannot or do not want to expose their users to the English token values.
Identifying equivalents for elements and vocabulary values can be challenging and may present barriers to semantic interoperability. For example, the common French translation for "Publisher" is diteur, a word that, along with the French rédacteur, can be taken to mean "editor". This difference in emphasis and association may create problems for the translation and use of French terms for the vocabulary values associated with 2.3.1 Lifecycle.Contribute.Role. Whenever possible, translated element titles and values should be accompanied with definitions that clarify their meaning.
The CEN/ISSS WS-LT has released two CEN Workshop Agreements (CWAs) providing further guidance for the use of the LOM in multilingual contexts:
CWA14643 "Internationalisation of the IEEE Learning Object Metadata"
http://www.cenorm.be/cenorm/businessdomains/businessdomains/informationsocietystandardizationsystem/published+cwas/cwa14643.pdf
CWA 14645 "Availability of alternative language versions of a learning resource in IEEE LOM"
http://www.cenorm.be/cenorm/businessdomains/businessdomains/informationsocietystandardizationsystem/published+cwas/cwa14645.pdf
4.2.7 Mapping Semantics
It is also possible to create meta-data application profiles through the refinement or mapping of the semantics implicitly and explicitly indicated in the data model. As in the case of the LOM conceptual data schema, the semantics of the element titles and vocabulary values are often not defined explicitly or in great detail. The precision of the meanings of these data elements can be increased in two ways.
Firstly, the LOM element or value may be mapped to a more precisely defined element or term in a related schema or element set. The more detailed or explicit definition from this related schema can then be applied to the LOM element or value. In addition, best or common practices associated with that element in the related schema can also be applied to the equivalent or associated LOM element or value. For example, definitions and practices established in the MARC community for the title of a published resource can be applied and adapted for use with the LOM General.Title element.
Secondly, the meaning of the LOM element or value can be defined through reference to best and common practices in the LOM community, or through use and interpretation of definitions provided in the Oxford English Dictionary, Second Edition, as recommended by the LOM conceptual data schema itself. In some meta-data communities e.g. Dublin Core, the product of these mapping and refinement activities is known as a "guidelines" document. In addition, if such refinements and mappings are created in the form of an application profile they can contribute to other profiling activities that focus more exclusively on the definition of element subsets and related constraints or extensions. An example of such a refinement and mapping activity relating directly to the LOM is provided by CanCore.
4.3 Implementation
4.3.1 Strict Implementation of the LOM Conceptual Data Schema
Meta-data creators may find their needs met by one or more of the existing conceptual data schema categories and its family of elements and vocabulary terms. These implementers do not need to go beyond the conceptual data schema as strict implementation meets their needs. This ensures the highest levels of semantic interoperability when exchanging meta-data instances between systems.
A strictly conforming LOM instance will only contain elements drawn from the LOM conceptual data schema schema and will not contain extensions. This does not imply that all LOM elements must be used in a strictly conforming instance.
Note that the conceptual data schema category Classification provides a mechanism for extending LOM as long as the information can be represented as a taxon path and does not introduce semantic ambiguity.
4.3.2 Extending the LOM Conceptual Data Schema
The LOM conceptual data schema intentionally provides elements and element groups that can be adapted for different purposes. It is recommended that elements should be adapted as per the LOM conceptual data schema rather than added as extensions. For example, instead of adding an element to accommodate thumbnail images of full size images, the elements in the Relation category can be adapted and used to meet this requirement. It is also recommended that the Classification category should be used to accommodate requirements that might otherwise be addressed by extensions. For example, the set of vocabulary terms in the Educational category cannot be expected to cover the diversity of educational practice globally. For attributes that cannot be covered in the Educational category, the Classification category may be used. However users should note that using the Classification category in this way might have a significant impact on semantic interoperability.
If community requirements cannot be accommodated within the data types and structures of the LOM conceptual data schema it may be necessary to create extensions. However implementers should recognize that extensions are, by their nature, community-specific and consequently will have a significant impact on both semantic and syntactic interoperability. While extensions will have meaning within a community of practice they are unlikely to be of relevance outside this community. Following the recommendations outlined in this section will help to maximize the interoperability of community specific meta-data extensions.
There are a variety of recommended methods for creating and managing LOM extensions. New elements or element categories may be created, element repetitions may be increased by altering the smallest permitted maximum and the length of CharacterStrings and LangStrings may be extended. In addition, vocabulary terms may be supplemented and new vocabularies created. Guidelines for extending vocabularies are outlined in sub-section 4.2.5 above.
If it is deemed necessary to create a new element or elements, then they should not replicate the coverage of existing elements. For example an "ISBN" element for encoding the ISBN of a resource should not be created, as this would replicate the General.Identifier.Entry element with General.Identifier.Catalog set to "ISBN".
In certain instances implementers may wish to describe categories of information that are not covered in detail by the LOM. The number of possible examples of such categories3 raises the prospect of an already large meta-data element set growing to an unmanageable size. Best advice at this time is that implementers should create a new element set describing the category of information that may be used independently or in conjunction with elements from the LOM and other meta-data schemata. New element sets should comprise elements from existing recognized meta-data standards or, where no appropriate elements exist, new elements may be created.
4.4 Exposing Meta-data
The IEEE LOM conceptual data schema says nothing about how meta-data should be stored and managed within a standalone environment. However, in order to facilitate interoperability, it is necessary for machine readable instances of meta-data to be exposed. To meet this requirement, the IEEE LTSC is publishing standards for binding LOM instances in various formats as part of the Standard for LOM. This section is concerned with the XML binding, IEEE 1484.12.3.
4.4.1 IEEE P1484.12.3 Standard for Extensible Markup Language (XML) Schema Definition Language Binding for Learning Object Metadata
Within the 1EdTech community, XML is the preferred encoding syntax for binding conceptual data schemata. The equivalent IEEE binding is documented as the IEEE P1484.12.3 Standard for Extensible Markup Language (XML) Schema Definition Language Binding for Learning Object Metadata [LOMBind, 05].
In conjunction with the normative IEEE standard for XML binding, the IEEE LTSC have released an informative XML schema that conforms to this standard4. Implementers of the XML schema can choose from a variety of options each of which reflect different design preferences. It should be noted that implicit or explicit choices must be made when binding a conceptual model such as the LOM conceptual data schema to an XML schema. For example, the LOM conceptual data schema requires that extension elements should not duplicate elements that are already part of the LOM. Conditions like this cannot be validated against an XML schema alone. As another example, some implementations assume that elements in a meta-data record appear in the order that they are listed in the LOM conceptual data schema. Such ordering may be built into a schema but such a schema would impose restrictions that do not exist in the LOM data model. A technical discussion of these issues appears in the IEEE standard for XML binding.
4.4.2 Application Profile Bindings and Conformance
Strictly conforming LOM instances must consist solely of LOM elements, they must conform to IEEE P1484.12.3 Standard for Extensible Markup Language (XML) Schema Definition Language Binding for Learning Object Metadata and should validate against the XML schema, lomStrict.xsd, that accompanies the draft standard. In addition to validating against the IEEE XML schema, implementers may choose to create their own schema for the sake of performance gains or in order to include any additional restrictions that they have placed on the data schema in the validation.
Customized LOM instances may include extensions of the type outlined in sub-section 4.3.2 above. Elements, element sets, or vocabularies that are used to extend the LOM should be identified by their own namespaces. Within the context of meta-data implementation a namespace may be defined as "a formal collection of terms managed according to a policy or algorithm" [Duval, 02]. While identifying community-specific extensions using namespaces helps to maximize potential interoperability, it should be noted that, in general, extensions have a negative impact on interoperability. Namespaces allow the identification of elements and vocabularies from sources outside the LOM conceptual data schema. When an application processes meta-data and encounters an extension namespace it may choose to read, store, or ignore the community-specific information depending on its capabilities
As meta-data is frequently stored in local databases that are only accessed by dedicated local applications, it is not necessary to mandate the form of the internal representation of the meta-data. However, if meta-data is going to be exposed for the purpose of data interchange, then specific commonly understood syntax is required and commonly adhered-to protocols imposed if this interchange is to be conducted as runtime transactions. Conforming LOM instances, including extensions, should adhere to the rules outlined in IEEE P1484.12.3 Standard for Extensible Markup Language (XML) Schema Definition Language Binding for Learning Object Metadata. In order to facilitate interoperability, it is recommended that conforming instances should validate against both the schema produced to accommodate the specific extensions of the application profile and, to enable data interchange, with the XML schemata that accompany the IEEE P1484.12.3 Standard for Extensible Markup Language (XML) Schema Definition Language Binding for Learning Object Metadata.
If extensions are created that do not adhere to the rules of IEEE P1484.12.3 Standard for Extensible Markup Language (XML) Schema Definition Language Binding for Learning Object Metadata the instance will be non-confroming.
4.4.3 Migration from 1EdTech LRM XML Binding to the IEEE 1484.12.3 Standard for Extensible Markup Language (XML) Schema Definition Language Binding for Learning Object Metadata
XML Style Sheet Transformations (XSLTs) have been created to facilitate the translation of existing 1EdTech LRM XML Binding Final Specification to the IEEE 1484.12.3 Standard for Extensible Markup Language (XML) Schema Definition Language Binding for Learning Object Metadata.
For more information see Appendix C.
4.4.4 Creating XML LOM Instances
LOM instances are expressed and bound in XML to provide a common and standardized means of facilitating functions such as search and discovery and for management in a distributed environment. The following practices are recommended for producing XML instances of LOM:
- Choose or develop an application profile appropriate for your organization or community of practice;
- Note that XML is intended to be machine generated and should not be written by hand;
- Care should be taken that XML instances validate against a publicly available and accessible schemata;
- Developers of new schemata should ensure that they conform to the LOM 1484.12.3 binding and that they are made publicly available at a persistent location.
Appendix A - Additional Resources
IEEE Standard for Learning Object Metadata (LOM)
1484.12.1 IEEE Standard for Learning Object Metadata (LOM) conceptual data schema can be found at: http://standards.ieee.org/
Information relating to the IEEE 1484.12.3 Standard for eXtensible Markup Language (XML) Schema Definition Language Binding for Learning Object Metadata can be found at: http://standards.ieee.org/
Further information about the IEEE Learning Object Metadata Working Group is available at: http://ltsc.ieee.org/wg12/index.html
The 1EdTech Learning Resource Meta-data specifications versions 1.0 - 1.3 can be found at: http://www.imsglobal.org/metadata/
A variety of vCard related links can be found at: http://www.imc.org/pdi/
The XML specification and additional links can be found at: http://www.w3.org/XML/
Information about the XML Namespaces recommendation can be found at: http://www.w3.org/TR/1999/REC-xml-names-19990114/
Baker, T. (2003) DCMI Usage Board Review of Application Profiles, Dublin Core Metadata Initiative
http://dublincore.org/usage/documents/profiles/
CORES Registry
http://www.cores-eu.net/registry/schema/
Duval, E., Hodgins, W., Sutton, S., & Weibel, S. (2002) Metadata Principles and Practicalities, D-Lib Magazine, Vol 8 (4)
http://www.dlib.org/dlib/april02/weibel/04weibel.html
Friesen, N., Mason, J. and Ward, N. (2002) Building Educational Metadata Application Profiles, Proceedings of the International Conference on Dublin Core and Metadata for e-Communities pp. 63-69, Florence: Firenze University Press
http://www.bncf.net/dc2002/program/ft/paper7.pdf
Kotok, A. (2002) Metadata Rules: A report from the Open Forum on Metadata Registries
http://www.webservices.org/index.php/article/articleview/922/1/24/
Ottawa (2001) The Ottawa Communique
http://www.ischool.washington.edu/sasutton/dc-ed/Ottawa-Communique.rtf
SC32/WG2 Home Page - Metadata Standards
http://metadata-stds.org
SCHEMAS Registry
http://www.schemas-forum.org/registry/desire/appprofile.php3
Guides to the LOM and Examples of Use
CanCore
The CanCore Profile is intended to facilitate the interchange of records describing educational resources and the discovery of these resources both in Canada and beyond its borders. CanCore is fully compatible with the IEEE LOM standard and provides best practice recommendations for all LOM elements.
CELEBRATE http://www.eun.org/eun.org2/eun/en/index_celebrate.cfm
CELEBRATE is outlining a pedagogy for eLearning in European schools based on a vision of what 'content' (resources + services + communication spaces) may look like in the future and how this will be created and delivered in online environments.
CETIS Metadata and Digital Repositories SIG http://metadata.cetis.ac.uk/
The UK Centre for Educational Technology Interoperability Standards meta-data advisory site. The SIG provides information on relevant specifications and standards, promotes the uptake of these specifications and standards, facilitates discussion among people using these specifications and standards and provides feedback to developers of future specifications and standards.
European Treasury Browser http://www.eun.org/eun.org2/eun/en/etb/sub_area.cfm?sa=441
The aim of the ETB project is to build a Web educational resource Metadata Networking infrastructure for schools in Europe, to link together existing national repositories, encourage new publication, and provide a reliable level of quality and structure.
The Le@rning Federation http://www.thelearningfederation.edu.au/repo/cms2/tlf/published/8519/Metadata_Application_Profile_1_3.pdf
The goal of The Le@rning Federation is for Australian education systems to collaboratively develop and provide a continuing supply of high quality online educational content.
MERLOT http://www.merlot.org/
MERLOT (Multimedia Educational Resource for Learning and Online Teaching) is a free and open resource designed primarily for faculty and students of higher education. Links to online learning materials such as learning objects are catalogued along with annotations such as peer reviews and assignments.
SCORM http://www.adlnet.org/
The Sharable Content Object Reference Model (SCORM) is a collection of specifications adapted from multiple sources to provide a comprehensive suite of e-learning capabilities that enable interoperability, accessibility and reusability of Web-based learning content.
UK LOM Core http://www.cetis.ac.uk/profiles/uklomcore
The UK LOM Core is an application profile of the IEEE LOM that has been optimized for use within the context of UK education. It provides a set of guidelines have been drafted to inform UK practitioners on the implementation of a minimum common core of LOM elements and associated vocabularies.
Appendix B - Mapping to Simple Dublin Core
Annex B to IEEE 1484.12.1 - 2002 Standard for LOM conceptual data model includes a mapping from the IEEE LOM to "Unqualified Dublin Core". The Dublin Core Metadata Element Set5 contains 15 simple, unqualified elements, which can be found at http://dublincore.org/documents/dces/. This element set has been formally endorsed by ISO, NISO, and a CEN Workshop Agreement, details of which are provided on the Dublin Core Metadata Initiative website. The elements in this set are stable and expected to remain so, however it should be noted that whereas Annex B of the LOM lists the DC element OtherContributer the stable Dublin Core element set uses Contributor.
The semantics of the unqualified Dublin Core elements are intentionally rather broad. It should be noted that the mapping is a one-way mapping, from the LOM to Dublin Core and that transforming meta-data from the IEEE LOM to unqualified Dublin Core will result in the loss of information. For example, the Dublin Core Date element could mean the date of authoring or the date of publication. The ability to populate an Unqualified Dublin Core record from an IEEE LOM instance will however remain useful to those who wish to interoperate with systems where Unqualified Dublin Core is recommended, for example those using Open Archives Initiative Protocol for Metadata Harvesting6.
The Dublin Core Metadata Initiative has developed Qualified Dublin Core which does not demand the losses described above. Dublin Core Metadata is also frequently included in Application Profiles. Specifically, some communities use special Dublin Core domain specific application profiles that are recommended by the DCMI Usage Board. The DC Education Application profile was developed with the LOM in mind and includes both DC and LOM originating elements.
Appendix C - 1EdTech LRM XML Binding IEEE LOM 1.0 XML Binding Transform
XSL Transforms (XSLTs) for transforming 1EdTech Learning Resource Meta-data Information Model Final Specification to IEEE 1484.12.1 - 2002 Standard for Learning Object Metadata have been written in conjunction with the work on this document. It includes numerous support files designed to help ensure the transformation suits the needs of any particular user, as well as, to illustrate the operation of the transform. It does not address best practices for transforming large numbers of documents, for deciding how and when to transition from 1EdTech Learning Resource Meta-data Information Model Final Specification to IEEE 1484.12.1 - 2002 Standard for Learning Object Metadata, or for archiving old 1EdTech LRM instances. It addresses the transform itself and how users may modify the transform to ensure that it addresses their needs.
Note that the XSLTs are a technical program and assume knowledge of XML. It may be necessary to augment or edit the transform to suit the specific needs of the user. Three transforms are supplied:
- Transform 1 - used to transform XML instances of 1EdTech LRM v1.2.1 to IEEE LOM v1.0;
- Transform 2 - used to transform XML instances of 1EdTech LRM v1.2.2 to IEEE LOM v1.0;
- Transform 3 - used to transform XML instances of 1EdTech LRM v1.2.4 to IEEE LOM v1.0.
You will find the XSLTs and supporting document at: http://www.imsglobal.org/metadata/.
Whenever possible the online LOM XSDs should be used for validation (all of the examples use the LOM XSD at URL: http://ltsc.ieee.org/xsd/lomv1.0/lomLoose.xsd). The 'Loose' version of the LOM binding is used to ensure that the set of vocabularies used in the 1EdTech LRM example instances do not create an invalid LOM instance (these examples were created long before the LOM vocabularies were established). If LOM valid vocabulary entries are used then the standards 'lom.xsd' binding should be used to make sure that the vocabulary values are correct.
About This Document
| Title | 1EdTech Meta-data Best Practice Guide for IEEE 1484.12.1-2002 Standard for Learning Object Metadata |
| Editor | Phil Barker, Lorna M. Campbell, Anthony Roberts, Colin Smythe |
| Version | 1.3 |
| Version Date | 31 August 2006 |
| Status | Final Specification |
| Summary | This document provides updated information regarding 1EdTech Meta-data Best Practice and Implementation Guide |
| Revision Information | August 2006 |
| Purpose | This document has been approved by the 1EdTech Technical Board and is made available for pubic adoption. |
| Document Location | http://www.imsglobal.org/metadata/mdv1p3/imsmd_bestv1p3.html |
| To register comments or questions about the specification, please visit: http://www.imsglobal.org/developers/ims/imsforum/categories.cfm?catid=3 |
List of Contributors
The following individuals contributed to the development of this document:
Revision History
Index
A
Application profile 1, 2, 3, 4, 5, 6, 7, 8, 9
ARIADNE 1, 2
C
CanCore 1, 2
CEN/ISSS 1, 2, 3, 4
D
Datatype 1, 2, 3, 4
Dublin Core 1, 2, 3, 4, 5, 6, 7
I
IEEE 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20
1EdTech Specifications
Meta-Data 1
Interoperability 1, 2, 3, 4, 5, 6, 7
L
Learning Resource 1, 2, 3, 4, 5, 6
LOM 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22
LRM 1, 2, 3, 4
LTSC 1, 2, 3, 4, 5
M
Meta-data 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
MIME 1, 2, 3
R
Registries 1
Resource 1, 2, 3, 4, 5, 6, 7, 8
RFC 1, 2, 3, 4
S
Schema 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
SCORM 1, 2, 3, 4
Standards 1, 2, 3, 4, 5, 6, 7, 8
Structure 1, 2, 3, 4, 5, 6
V
vCard 1, 2, 3
Vocabularies 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14
Vocabulary 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16
W
W3C 1
X
XML 1, 2, 3, 4, 5, 6, 7, 8, 9, 10
XSL 1, 2, 3, 4
XSLT 1
1EdTech Consortium, Inc. ("1EdTech/GLC") is publishing the information contained in this 1EdTech Meta-data Best Practice Guide for IEEE 1484.12.1-2002 Standard for Learning Object Metadata ("Specification") for purposes of scientific, experimental, and scholarly collaboration only.
1EdTech/GLC makes no warranty or representation regarding the accuracy or completeness of the Specification.
This material is provided on an "As Is" and "As Available" basis.
The Specification is at all times subject to change and revision without notice.
It is your sole responsibility to evaluate the usefulness, accuracy, and completeness of the Specification as it relates to you.
1EdTech/GLC would appreciate receiving your comments and suggestions.
Please contact 1EdTech/GLC through our website at http://www.imsglobal.org
Please refer to Document Name: 1EdTech Meta-data Best Practice Guide for IEEE 1484.12.1-2002 Standard for Learning Object Metadata Revision: 31 August 2006
